In this note, I will visually demonstrate how the transition of lgwr from poll->post to post/wait mode can look like.
Investigate time when it happened by using trace file of lgwr process:
*** 2023-02-16T12:45:09.010167+06:00
Log file sync switching to post/wait
Current approximate redo synch write rate is 10286 per sec
Fig.1Fig.2
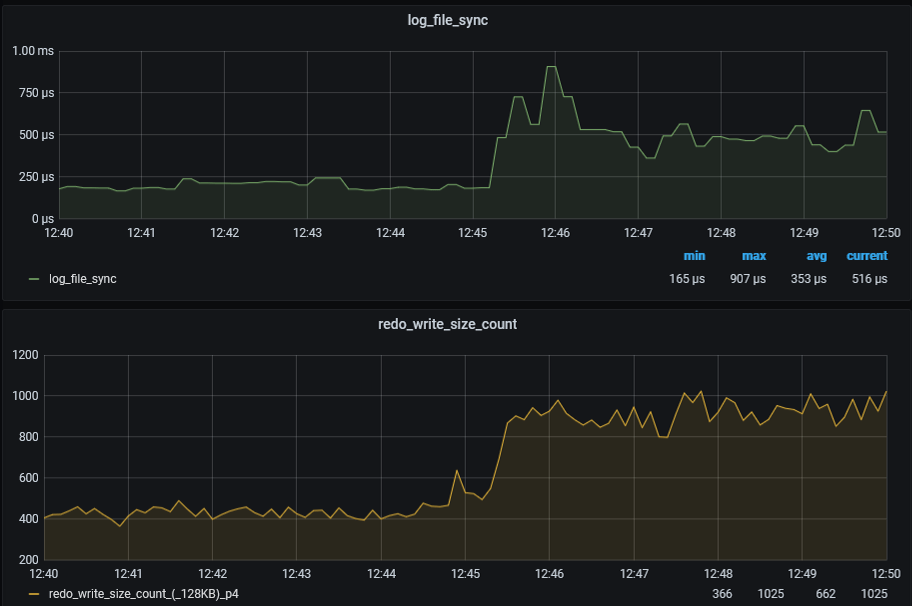
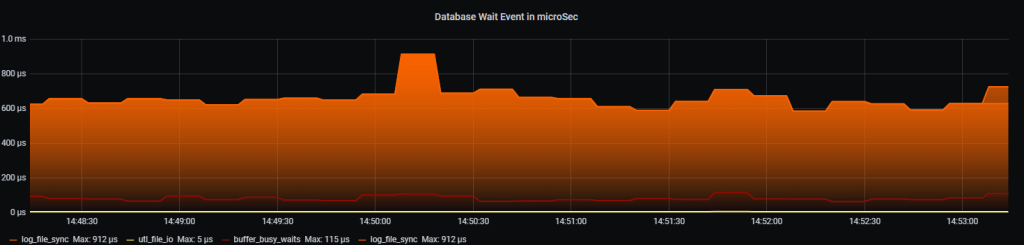
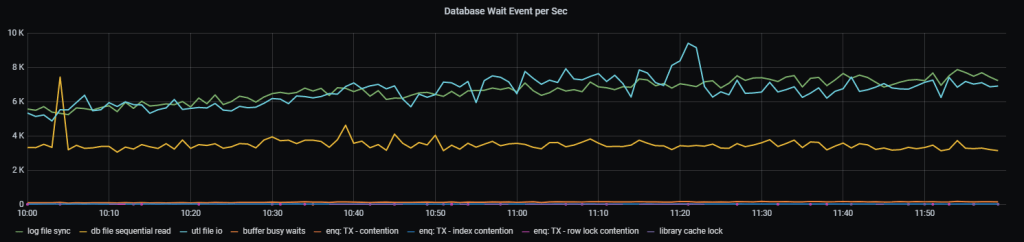
Figure 1 shows that the transition of lgwr from poll->post to post/wait mode led to a doubling of the log file sync wait time, from 250 microseconds to 500 microseconds. Additionally, the number of redo blocks written in 128KB doubled. Although not visible in the graphs, there is also a decrease in the number of redo blocks written that are much smaller than 128KB (4, 8, 16, 32KB, etc).
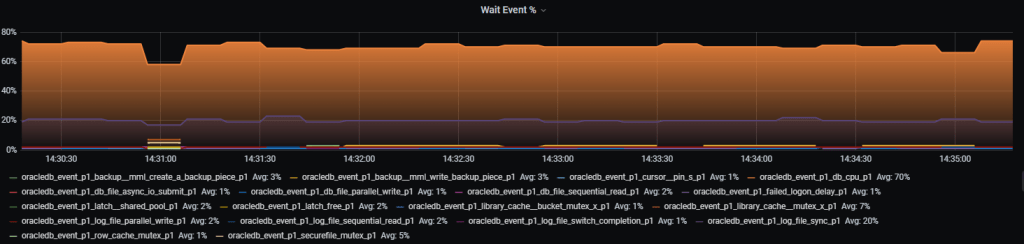
Figure 2 shows how the number of log file parallel write waits (oracledb_event_p3_log_file_parallel_write_p2) has changed. The number of waits has decreased by half, but the duration of a single log file parallel write wait (oracledb_event_p2_log_file_parallel_write_p2) has increased by an average of 50%, from 50 microseconds to 75 microseconds.
It looks like some sort of ferry mode where fewer operations are performed with larger block sizes, resulting in a 2x reduction in response time. This behavior is subject to change according to the algorithm and database parameters associated with the adaptive operation of LGWR.
You can read more here:
Adaptive Switching Between Log Write Methods can Cause ‘log file sync’ Waits (Doc ID 1462942.1)
If you have made export using FULL=y CONTENT=metadata_only from 19.3 db version, it is unable to import dump in 19.9 the cause of an error is ORA-02376: invalid or redundant resource.
If you search ORA-02376 on MOS you can find «DataPump Import Fails With Duplicated Resources In The Create Profile Statement (Doc ID 557383.1)», but this is not our case. The root of the problem is user profile which has PASSWORD_ROLLOVER_TIME option introduced from 19.12 according to Gradual Database Password Rollover. Creating profile with PASSWORD_ROLLOVER_TIME option produces an error ORA-02376 on db version lower than 19.12. I tested only 19.9. Export from 19.12 version and higher with parameter version=19.9, or 19.0, or 12.0 didn’t help.
You must skip profile from export and make it manually.
Сделав экcпорт FULL=y CONTENT=metadata_only из бд 19.13, не получается залить дамп в 19.9 по причине ORA-02376: invalid or redundant resource.
На MOS по ошибке ORA-02376 есть нота, DataPump Import Fails With Duplicated Resources In The Create Profile Statement (Doc ID 557383.1), но она не про этот случай.
Корень проблемы в том, что с 19.12 в профиле для пользователей появилась опция PASSWORD_ROLLOVER_TIME в рамках Gradual Database Password Rollover.
При попытке провести импорт дампа, снятого из 19.12 и выше, в бд версии 19.11 и ниже (я проверил только 19.9) создание профиля ломается на ошибке ORA-02376, а далее не создаются пользователи и т.д.
Создать вручную профиль с опцией PASSWORD_ROLLOVER_TIME в 19.9 тоже не получится, эта версия просто не знает про такие опции.
Экспорт с параметром version=19.9, или 19.0 или 12.0 проблему не решает… Переносим профиля отдельно, и заливаем дамп.
upd. 25.03.2025, данная статья устарела, но полезна для общего развития, т.к. здесь была положена идея(в 2021г), которая преобразовалась в kPerf for Oracle
—————————————————————————————————————
Контроль стабильности работы бд требует мониторинга и понимания метрик этого мониторинга. В связи с этим я написал свой небольшой снапер метрик бд и вложил в него ‘своё’ восприятие этих метрик для своих нужд, но возможно общая идея будит интересна ещё кому ни будь.
Мониторинг состоит из нескольких компонентов:
Набор таблиц
Задание по расписанию для заполнения таблиц из пункта 1
Получение данных из таблиц пункта 1 и передача этих данных.
Grafana
Prometheus
OracleDB exporter
Инструкция не содержит пошаговой настройки всех компонентов, а только показывает, как собирается статистика в бд и как обрабатывается.
Набор таблиц.
1.1
CREATE SEQUENCE system.kks$sys_wait_event_sequence
MINVALUE 1
MAXVALUE 999999999999999999999999999
START WITH 1
INCREMENT BY 1
CACHE 20;
create table system.kks$system_wait_event(
wait_class varchar2(256),
TOTAL_WAITS_sum number,
TIME_WAITED_MICRO_sum number,
snap_time date default sysdate,
snap_id number
)
tablespace sysaux;
create index SYSTEM.snap_time_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT (snap_time) tablespace sysaux;
create index SYSTEM.wait_class_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT (wait_class) tablespace sysaux;
create index SYSTEM.snap_id_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT (snap_id) tablespace sysaux;
1.2
CREATE SEQUENCE system.kks$sys_wait_event_sequence_p1
MINVALUE 1
MAXVALUE 999999999999999999999999999
START WITH 1
INCREMENT BY 1
CACHE 20;
create table system.kks$system_wait_event_p1(
wait_event varchar2(256),
TOTAL_WAITS_sum number,
TIME_WAITED_MICRO_sum number,
snap_time date default sysdate,
snap_id number
)
tablespace sysaux;
create index SYSTEM.snap_time_p1_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT_p1 (snap_time) tablespace sysaux;
create index SYSTEM.wait_event_p1_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT_p1 (wait_event) tablespace sysaux;
create index SYSTEM.snap_p1_id_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT_p1 (snap_id) tablespace sysaux;
1.3
CREATE SEQUENCE system.kks$sys_wait_event_sequence_p2
MINVALUE 1
MAXVALUE 999999999999999999999999999
START WITH 1
INCREMENT BY 1
CACHE 20;
create table system.kks$system_wait_event_p2(
wait_event varchar2(256),
TOTAL_WAITS_sum number,
TIME_WAITED_MICRO_sum number,
snap_time date default sysdate,
snap_id number
)
tablespace sysaux;
create index SYSTEM.snap_time_p2_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT_p2 (snap_time) tablespace sysaux;
create index SYSTEM.wait_event_p2_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT_p2 (wait_event) tablespace sysaux;
create index SYSTEM.snap_p2_id_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT_p2 (snap_id) tablespace sysaux;
2. Задание по расписанию для заполнения таблиц из пункта 1
2.1
Заполняем таблицу из пункта 1.1. Делаем снапшот суммарного количества ожиданий по каждому классу ожиданий(WAIT_CLASS) и суммарного количества времени отведённого для каждого класса ожиданий(WAIT_CLASS), устаревшие данные удалям.
declare
seqno number;
begin
select system.kks$sys_wait_event_sequence.nextval into seqno from dual;
insert into system.kks$system_wait_event(wait_class,total_waits_sum,time_waited_micro_sum,snap_id)
select w.WAIT_CLASS,sum(w.TOTAL_WAITS) totalwaits,sum(w.TIME_WAITED_MICRO) mcsec,seqno from v$system_event w
where w.WAIT_CLASS!='Idle'
group by w.WAIT_CLASS;
insert into system.kks$system_wait_event(wait_class,time_waited_micro_sum,snap_id)
select o.STAT_NAME,o.VALUE,seqno from V$SYS_TIME_MODEL o where o.STAT_NAME='DB CPU';
commit;
delete from system.kks$system_wait_event p1 where p1.snap_time<=sysdate-30/24/60;
commit;
end;
2.2
Заполняем таблицу из пункта 1.2. Делаем снапшот суммарного количества ожиданий по каждому ожиданию(EVENT) и суммарного количества времени отведённого для каждого ожидания(EVENT), устаревшие данные удалям.
declare
seqno number;
begin
select system.kks$sys_wait_event_sequence_p1.nextval into seqno from dual;
insert into system.kks$system_wait_event_p1(wait_event,total_waits_sum,time_waited_micro_sum,snap_id)
select w.EVENT,sum(w.TOTAL_WAITS) totalwaits,sum(w.TIME_WAITED_MICRO) mcsec,seqno from v$system_event w
where w.WAIT_CLASS!='Idle' and w.EVENT!='SQL*Net message to client'
group by w.EVENT;
insert into system.kks$system_wait_event_p1(wait_event,time_waited_micro_sum,snap_id)
select o.STAT_NAME,o.VALUE,seqno from V$SYS_TIME_MODEL o where o.STAT_NAME='DB CPU';
commit;
delete from system.kks$system_wait_event_p1 p1 where p1.snap_time<=sysdate-30/24/60;
commit;
end;
2.3
Заполняем таблицу из пункта 1.3. Делаем снапшот суммарного количества ожиданий по каждому ожиданию(EVENT) и суммарного количества времени отведённого для каждого ожидания(EVENT), устаревшие данные удалям.
declare
seqno number;
begin
select system.kks$sys_wait_event_sequence_p2.nextval into seqno from dual;
insert into system.kks$system_wait_event_p2(wait_event,total_waits_sum,time_waited_micro_sum,snap_id)
select w.EVENT,sum(w.TOTAL_WAITS) totalwaits,sum(w.TIME_WAITED_MICRO) mcsec,seqno from v$system_event w
where w.WAIT_CLASS!='Idle' and w.EVENT!='SQL*Net message to client'
group by w.EVENT;
commit;
delete from system.kks$system_wait_event_p2 p1 where p1.snap_time<=sysdate-30/24/60;
commit;
end;
Я заполняю эти таблицы каждые 5сек. Возможно 2.3 избыточен, т.к. почти такие же данные есть в 2.2. Но тут кроется ‘моя’ особая логика, 2.2 нужен для анализа ожиданий в процентном отношении с учётом DB CPU.
3. Получение данных из таблиц пункта 1 и передача этих данных.
Получение значений ожиданий по каждому классу ожиданий, выраженное в процентах. Сумма всех классов ожиданий не превышает 100%
[[metric]]
context = "db_wait_event"
metricsdesc= { value="System wait event time Diff in %" }
fieldtoappend= "wait_class"
request = '''
with
waitpcts1 as (
select sum(p.time_waited_micro_sum) as timewait1, p.snap_id as snap_id1 from system.kks$system_wait_event p
where p.snap_id=(select max(snap_id) from system.kks$system_wait_event)
group by p.snap_id),
waitpcts2 as (
select sum(p.time_waited_micro_sum) as timewait2,p.snap_id as snap_id2 from system.kks$system_wait_event p
where p.snap_id=(select max(snap_id)-1 from system.kks$system_wait_event)
group by p.snap_id),
wait1 as (
select p.wait_class as wait_class1,p.time_waited_micro_sum as time_waited_micro_sum1,p.snap_id as snap_id1 from system.kks$system_wait_event p
where p.snap_id=(select max(snap_id) from system.kks$system_wait_event)),
wait2 as (
select p.wait_class as wait_class2,p.time_waited_micro_sum as time_waited_micro_sum2,p.snap_id as snap_id12 from system.kks$system_wait_event p
where p.snap_id=(select max(snap_id)-1 from system.kks$system_wait_event))
select wait1.wait_class1 as "wait_class",
round(((wait1.time_waited_micro_sum1-wait2.time_waited_micro_sum2)/decode((waitpcts1.timewait1-waitpcts2.timewait2),0,1,(waitpcts1.timewait1-waitpcts2.timewait2)))*100) as "value"
from wait1,wait2,waitpcts1,waitpcts2
where wait1.wait_class1=wait2.wait_class2
'''
Как это выглядит:
Рис.1
3.2 Получение значения времени по каждому ожиданию(event)(сколько времени потрачено на одно ожидание) выраженное в процентах. Сумма всех ожиданий не превышает 100%.
[[metric]]
context = "event_p1"
metricsdesc= { value="System wait event P1 Diff in % }
fieldtoappend= "wait_event_p1"
request = '''
with
waitpcts1 as (
select sum(p.time_waited_micro_sum) as timewait1, p.snap_id as snap_id1 from system.kks$system_wait_event_p1 p
where p.snap_id=(select max(snap_id) from system.kks$system_wait_event_p1)
group by p.snap_id),
waitpcts2 as (
select sum(p.time_waited_micro_sum) as timewait2,p.snap_id as snap_id2 from system.kks$system_wait_event_p1 p
where p.snap_id=(select max(snap_id)-1 from system.kks$system_wait_event_p1)
group by p.snap_id),
wait1 as (
select p.wait_event as wait_event1,p.time_waited_micro_sum as time_waited_micro_sum1,p.snap_id as snap_id1 from system.kks$system_wait_event_p1 p
where p.snap_id=(select max(snap_id) from system.kks$system_wait_event_p1)),
wait2 as (
select p.wait_event as wait_event2,p.time_waited_micro_sum as time_waited_micro_sum2,p.snap_id as snap_id12 from system.kks$system_wait_event_p1 p
where p.snap_id=(select max(snap_id)-1 from system.kks$system_wait_event_p1))
select replace(replace(replace(wait1.wait_event1,':','_'),'-','_'),'&','_')||'_p1' as "wait_event_p1",
ceil(((wait1.time_waited_micro_sum1-wait2.time_waited_micro_sum2)/decode((waitpcts1.timewait1-waitpcts2.timewait2),0,1,(waitpcts1.timewait1-waitpcts2.timewait2)))*100) as "value"
from wait1,wait2,waitpcts1,waitpcts2
where wait1.wait_event1=wait2.wait_event2
and ceil(((wait1.time_waited_micro_sum1-wait2.time_waited_micro_sum2)/decode((waitpcts1.timewait1-waitpcts2.timewait2),0,1,(waitpcts1.timewait1-waitpcts2.timewait2)))*100)>0
'''
Как это выглядит:
Рис.2
3.3 Сколько времени потрачено на одно событие ожидания(event) в микросекундах.
[[metric]]
context = "event_p2"
metricsdesc= { value="System wait event time P2 Diff in micsec for 4sec." }
fieldtoappend= "wait_event_p2"
request = '''
with
waitpcts1 as (
select p.wait_event as waitevent1,
p.time_waited_micro_sum as timewait1,
p.total_waits_sum as totalwaits1,
p.snap_id as snap_id1
from system.kks$system_wait_event_p2 p
where p.snap_id=(select max(snap_id) from system.kks$system_wait_event_p2)),
waitpcts2 as (
select p.wait_event as waitevent2,
p.time_waited_micro_sum as timewait2,
p.total_waits_sum as totalwaits2,
p.snap_id as snap_id2
from system.kks$system_wait_event_p2 p
where p.snap_id=(select max(snap_id)-1 from system.kks$system_wait_event_p2))
select replace(replace(replace(waitpcts1.waitevent1,':','_'),'-','_'),'&','_')||'_p2' as "wait_event_p2",
ceil(((waitpcts1.timewait1-waitpcts2.timewait2)/decode((waitpcts1.totalwaits1-waitpcts2.totalwaits2),0,1,(waitpcts1.totalwaits1-waitpcts2.totalwaits2)))) as "value"
from waitpcts1,waitpcts2
where waitpcts1.waitevent1=waitpcts2.waitevent2
and ceil(((waitpcts1.timewait1-waitpcts2.timewait2)/decode((waitpcts1.totalwaits1-waitpcts2.totalwaits2),0,1,(waitpcts1.totalwaits1-waitpcts2.totalwaits2))))>0
'''
Как это выглядит:
Рис.3
3.3 Количество событий по каждому ожиданию(event) в секунду
[[metric]]
context = "event_p3"
metricsdesc= { value="System wait events P3 Diff for 4sec." }
fieldtoappend= "wait_event_p3"
request = '''
with
waitpcts1 as (
select p.wait_event as waitevent1,
p.total_waits_sum as totalwaits1,
p.snap_id as snap_id1
from system.kks$system_wait_event_p2 p
where p.snap_id=(select max(snap_id) from system.kks$system_wait_event_p2)),
waitpcts2 as (
select p.wait_event as waitevent2,
p.total_waits_sum as totalwaits2,
p.snap_id as snap_id2
from system.kks$system_wait_event_p2 p
where p.snap_id=(select max(snap_id)-1 from system.kks$system_wait_event_p2))
select
replace(replace(replace(waitpcts1.waitevent1,':','_'),'-','_'),'&','_')||'_p2' as "wait_event_p3",
ceil((waitpcts1.totalwaits1-waitpcts2.totalwaits2)/4) as "value"
from waitpcts1,waitpcts2
where waitpcts1.waitevent1=waitpcts2.waitevent2 and ceil(waitpcts1.totalwaits1-waitpcts2.totalwaits2)>0
'''
Как это выглядит:
Рис.4
upd. 25.03.2025, данная статья устарела, но полезна для общего развития, т.к. здесь была положена идея(в 2021г), которая преобразовалась в kPerf for Oracle
Я буду отключать диски, и наблюдать, как поведёт себя ASM и база данных, а также данная статья призвана пролить свет на количественные характеристики показателей свободного, занятого, и прочего места в ASM, при проведение эксперимента и ответить на вопрос ‘а что если..?’.
Версия ASM 12.1.0.2.190716
Конфигурация: Дисковая группа из шести дисков и двух Failgroup, по 3 диска в каждой FG, с избыточностью Normal.
SQL> create diskgroup kksdg1 normal redundancy failgroup fg1 disk 'ORCL:DISK1','ORCL:DISK2','ORCL: DISK7' failgroup fg2 disk 'ORCL:DISK3','ORCL:DISK4','ORCL:DISK4N';
Diskgroup created.
Req_mir_free_MB — зарезервировал по одному диску на каждую failgroup, и того зарезервировано 2 диска.
Все диски в дисковой группе заполнились равномерно(внимание на колонку Free_MB).
1.2 Проверим устойчивость дисковой группы к выходу из строя дисков:
Я выставил ‘DISK_REPAIR_TIME’=’1m’ для дисковой группы.
1.2.1 Отключаем первый диск(DISK1):
[root@kks grid12]# oracleasm querydisk -d DISK1
Disk "DISK1" is a valid ASM disk on device [8,81]
[root@kks grid12]# ls -l /dev/* | grep 8, | grep 81
brw-rw---- 1 root disk 8, 81 Aug 5 15:56 /dev/sdf1
[root@kks grid12]# echo 1 > /sys/block/sdf/device/delete
ASM Alert log:
Wed Aug 05 16:24:36 2020
Errors in file /grid/app/diag/asm/+asm/+ASM/trace/+ASM_gmon_2966.trc:
ORA-15186: ASMLIB error function = [kfk_asm_ioerror], error = [0], mesg = [I/O Error]
Wed Aug 05 16:24:36 2020
NOTE: PST update grp = 2 completed successfully
Wed Aug 05 16:25:22 2020
WARNING: Started Drop Disk Timeout for Disk 0 (DISK1) in group 2 with a value 60
WARNING: Disk 0 (DISK1) in group 2 will be dropped in: (60) secs on ASM inst 1
DB Alert log:
Wed Aug 05 16:24:36 2020
NOTE: updating disk modes to 0x5 from 0x7 for disk 0 (DISK1) in group 2 (KKSDG1): lflags 0x0
NOTE: disk 0 (DISK1) in group 2 (KKSDG1) is offline for reads
NOTE: updating disk modes to 0x1 from 0x5 for disk 0 (DISK1) in group 2 (KKSDG1): lflags 0x0
NOTE: disk 0 (DISK1) in group 2 (KKSDG1) is offline for writes
ASM Alert log:
Wed Aug 05 16:28:29 2020
SUCCESS: alter diskgroup KKSDG1 drop disk DISK1 force /* ASM SERVER */
По прошествии нескольких минут диск был удалён, ребаланс прошел успешно.
1.2.2 Отключаем второй диск(DISK2):
[root@kks grid12]# oracleasm querydisk -d DISK2
Disk "DISK2" is a valid ASM disk on device [8,129]
[root@kks grid12]# ls -l /dev/* | grep 8, | grep 129
brw-rw---- 1 root disk 8, 129 Aug 5 15:56 /dev/sdi1
[root@kks grid12]# echo 1 > /sys/block/sdi/device/delete
ASM Alert log:
Wed Aug 05 16:34:44 2020
WARNING: Started Drop Disk Timeout for Disk 1 (DISK2) in group 2 with a value 60
WARNING: Disk 1 (DISK2) in group 2 will be dropped in: (60) secs on ASM inst 1
Errors in file /grid/app/diag/asm/+asm/+ASM/trace/+ASM_gmon_2966.trc:
ORA-15186: ASMLIB error function = [kfk_asm_ioerror], error = [0], mesg = [I/O Error]
…………………………………..
Wed Aug 05 16:37:51 2020
SUCCESS: alter diskgroup KKSDG1 drop disk DISK2 force /* ASM SERVER */
DB Alert log:
Wed Aug 05 16:32:47 2020
NOTE: updating disk modes to 0x5 from 0x7 for disk 1 (DISK2) in group 2 (KKSDG1): lflags 0x0
NOTE: disk 1 (DISK2) in group 2 (KKSDG1) is offline for reads
NOTE: updating disk modes to 0x1 from 0x5 for disk 1 (DISK2) in group 2 (KKSDG1): lflags 0x0
NOTE: disk 1 (DISK2) in group 2 (KKSDG1) is offline for writes
На данном этапе получилось, что ребаланc завешается ошибкой ORA-15041, недостаточно места в дисковой группе и в FG1 в частности, чтобы провести ребаланс.
Данный диск _DROPPED_0001_KKSDG1 не удаляется, а переименовался, бд по-прежнему доступна и таблицы в табличном пространстве kkstbs1 тоже живы, также Usable_file_MB в минусе.
В Alert log BD:
Wed Aug 05 16:37:51 2020
SUCCESS: disk DISK2 (1.3916017828) renamed to _DROPPED_0001_KKSDG1 in diskgroup KKSDG
1.2.3 Отключаем третий диск(DISK7):
[root@kks grid12]# oracleasm querydisk -d DISK7
Disk "DISK2" is a valid ASM disk on device [8, 161]
[root@kks ~]# ls -l /dev/* | grep 8, | grep 161
brw-rw---- 1 root disk 8, 161 Aug 6 13:17 /dev/sdk1
[root@kks ~]# echo 1 > /sys/block/sdk/device/delete
Остановим бд и перемонтируем дисковую группу, проверим, не потеряю ли я группу на данном этапе:
SQL> alter diskgroup kksdg1 dismount;
Diskgroup altered.
SQL> alter diskgroup kksdg1 mount;
Diskgroup altered.
Может показаться, что если невозможно провести ребаланс, по причине ошибки ORA-15041, ASM не удалят диски, а переименовывает их.
Но это только показалось, в ходе эксперимента было десятки кейсов удаления дисков, и поведение может отличаться. Например, если удалить, созданное на этой дисковой группе табличное пространство kkstbs1, то произойдёт это:
SUCCESS: grp 2 disk _DROPPED_0000_KKSDG1 going offline
SUCCESS: grp 2 disk _DROPPED_0001_KKSDG1 going offline
NOTE: Disk _DROPPED_0000_KKSDG1 in mode 0x0 marked for de-assignment
NOTE: Disk _DROPPED_0001_KKSDG1 in mode 0x0 marked for de-assignment
диски удалятся, но последующие несколько экспериментов показали, что это не всегда так.
Какой в этом смысл? Зачем держать эти диски, которых фактически нет.
Также, если удалять дисковую группу через drop diskgroup force including contents, то повторное использование дисков не требует зачистки их заголовков через dd, если использовать просто drop diskgroup, то нужно чистить заголовок диска, чтобы его повторно использовать(это особенность asm 12), force можно применить если группа не замонтирована.
И на сладкое, двойное удаление дисковой группы(тест на то, что заголовки дисков живы после удаления группы):
SQL> drop diskgroup kksdg1 force including contents;
drop diskgroup kksdg1 force including contents
*
ERROR at line 1:
ORA-15039: diskgroup not dropped
ORA-15230: diskgroup 'KKSDG1' does not require the FORCE option
SQL> drop diskgroup kksdg1;
Diskgroup dropped.
SQL> drop diskgroup kksdg1 force including contents;
drop diskgroup kksdg1 force including contents
*
ERROR at line 1:
ORA-15039: diskgroup not dropped
ORA-15063: ASM discovered an insufficient number of disks for diskgroup
"KKSDG1"
SQL> alter diskgroup kksdg1 mount;
alter diskgroup kksdg1 mount
*
ERROR at line 1:
ORA-15032: not all alterations performed
ORA-15017: diskgroup "KKSDG1" cannot be mounted
ORA-15040: diskgroup is incomplete
SQL> drop diskgroup kksdg1 force including contents; <----- Здесь я вернул отключенные диски(просканировав шину SCSI ) и смогу удалить дисковую группу ещё раз 0_о
Diskgroup dropped.
SQL>
Вероятно будет часть 3 и версия asm 19, с применением утилит ASM tools used by Support : KFOD, KFED, AMDU (Doc ID 1485597.1), т.к. как всегда(у меня), вопросов больше, чем ответов.
Случается так, что нельзя очистить инциденты из OEM13c.
Инцидент может быть просто не ‘кликабельным’ и виден он только если перейти в таргет, затем в All Metrics, увидим Open Metric Events , а в Incident Manager его нет.
Также выполнение всех требований (This incident will be automatically cleared when the underlying issue is resolved.) по его устранению не вызывает авто удаление инцидента.
Либо инцидентов может быть слишком много, чтобы быстро зачистить их с веб-консоли.
Я знаю два варианта решения этих проблем:
1. Используя утилиту emcli.
Подключаемся к репозитарию OEM13c и запросом строим скрипт по зачистке:
select a.adr_related,a.problem_num,b.target_name, a.incident_num, a.severity, a.creation_date, a.summary_msg,
q'!emcli delete_incident_record -force -incident_number_list=!'||a.incident_num scr_incident,
q'!emcli delete_incident_record -force -incident_number_list=!'||a.problem_num scr_problem
from mgmt$incidents a, mgmt$target b, mgmt$INCIDENT_CATEGORY c
where a.target_guid=b.target_guid
and a.incident_id=c.incident_id
--and a.summary_msg like '%MesageName%'
--and adr_related=0
and b.target_name like 'targetName%'
--and a.incident_num=78381
and a.severity!='Clear'
В колонках scr_incident и scr_problem будет сгенерирована строка на каждый инцидент/проблему для удаления. Фильтровать можно по имени таргета, инциденту, или куску текста из сообщения об инциденте.
Далее логинемся по ssh на сервер где установлен Weblogic, переходим в MW_HOME/bin и выполняем:
emcli login -username=sysman
Enter password : <------ Указываем пароль для SYSMAN
Теперь выполняем команду на удаление полученную из скрипта:
[oracle]$ emcli delete_incident_record -force -incident_number_list=218893
=========
Results
=========
=> Incident 218,893 has been successfully deleted.
Если же при выполнении удаления инцидента есть сообщения вида:
Incident 201,646 cannot be deleted. It may be closed, does not exist or is not accessible to this user.
Или
Incident 104,021 is a diagnostic incident and cannot be deleted.
Тогда переходим к варианту номер два.
2. Вычистить данные об инцидентах из бд репозитория.
Подключаемся к репозитарию OEM. Создаём две таблицы(можете использовать свой вариант, главное запомнить эти ID), в которые запишем ID инцидентов, которые хотим удалить. Одна таблица будет содержать ISSUE_ID другая EVENT_INSTANCE_ID. Я собираю ISSUE_ID и EVENT_INSTANCE_ID для инцидентов связанных с ошибкой ORA 3137:
create table KKS$ISSUE_ID as select pp.ISSUE_ID from em_issues_msg pp where pp.SUMMARY_MSG like '%ORA 3137%'
create table KKS$EVENT_INSTANCE_ID as select oo.EVENT_INSTANCE_ID from EM_EVENT_MSGS oo where msg like '%ORA 3137%'
Далее генерируем скрипт по удалению данных для ISSUE_ID:
select q'!delete from !'||s.TABLE_NAME ||q'! e1 where !'
|| case s.COLUMN_NAME when 'ISSUE_ID' then q'!ISSUE_ID in (select issue_id from KKS$ISSUE_ID);!'
when 'INCIDENT_ID' then q'!ISSUE_ID in (select issue_id from KKS$ISSUE_ID);!'
when 'EVENT_INSTANCE_ID' then q'!EVENT_INSTANCE_ID in (select p3.event_instance_id from KKS$EVENT_INSTANCE_ID p3);!'
else q'!Wrong column !'||s.COLUMN_NAME
end
from dba_tab_cols s where s.COLUMN_NAME='ISSUE_ID'; ---<<<<----- условие ISSUE_ID
Затем для EVENT_INSTANCE_ID:
select q'!delete from !'||s.TABLE_NAME ||q'! e1 where !'
|| case s.COLUMN_NAME when 'ISSUE_ID' then q'!ISSUE_ID in (select issue_id from KKS$ISSUE_ID);!'
when 'INCIDENT_ID' then q'!ISSUE_ID in (select issue_id from KKS$ISSUE_ID);!'
when 'EVENT_INSTANCE_ID' then q'!EVENT_INSTANCE_ID in (select p3.event_instance_id from KKS$EVENT_INSTANCE_ID p3);!'
else q'!Wrong column !'||s.COLUMN_NAME
end
from dba_tab_cols s where s.COLUMN_NAME='EVENT_INSTANCE_ID';---<<<<----- условие EVENT_INSTANCE_ID
Эти два скрипта генерируют выражение delete для таблиц у которых встречается колонка SSUE_ID или EVENT_INSTANCE_ID в связке с нашими таблицами которые мы создали ранее.
Метод номер два гораздо опаснее чем метод номер один. Перед его применением просчитайте варианты отката бд к моменту до удаление(как вариант, используйте точку восстановления).
И есть нота на MOS: EVENT: DROP_SEGMENTS — Forcing cleanup of TEMPORARY segments (Doc ID 47400.1). Но всё выше описанное может ‘показаться’ не рабочим или ресурсоёмким.
Я пройдусь по возможным вариантам(а может есть ещё варианты ?), как избежать enq: ss- contention:
1. Выполнить ‘какой либо’ resize.
Это может быть, как добавление темп файлов, так и выполнение shrink табличного пространства или coalesce.
Данный метод неэффективен (сколько можно добавлять файлов?) и ресурсоёмким, шринк/coalesce темпа создаёт нагрузку на ввод-вывод (регулярно это делать- сомнительное дело).
2. Выполнить рекомендацию из ноты 47400.1
Если выполнить так как описано, то с виду будет выглядеть так, как будто решение alter session set events ‘immediate trace name DROP_SEGMENTS level TS#+1 не работает, эффект будет не заметен.
Первый вариант выглядит нерациональным, но если выбора нет, то и он сойдёт)))
А вот второй вариант выглядит более интересным, и он описан в блоге ebs12blog.wordpress.com(ссылка выше).
И тут главное не упустить две важные детали:
1. Выполнять alter session set events ‘immediate trace name DROP_SEGMENTS level TS#+1 нужно в цикле, т.к. за одно выполнение освобождается определённое количество (или % ?) экстентов.
2. Выполнять нужно на каждом экземпляре бд (для освобождения не занятых экстентов, и дальнейшего равномерного использования по всем экземплярам) или на том экземпляре, где больше всего свободных экстентов.
После выполнения скрипта на каждом инстансе бд, выглядит это так (gv$sort_segment):
Нет занятых и свободных. 🙂
Регулярное выполнение DROP_SEGMENTS level TS#+1 на нодах, побочных эффектов не выявило. Версия бд 12.1.0.2
Данная статья призвана пролить свет на количественные характеристики показателей свободного, занятого и прочего места в ASM, т.к. иногда возникают вопросы.
Версия ASM 12.1.0.2.190716 Конфигурация 1: Дисковая группа из двух дисков с избыточностью Normal.
Создаём группу с нормальной(двойной избыточностью):
SQL> CREATE DISKGROUP testkks1 normal REDUNDANCY DISK 'ORCL:DISK1','ORCL:DISK2';
Diskgroup created.
Usable_file_MB- свободного (защищенного) места с учетом избыточности
Req_mir_free_MB- количество пространства, которое требуется для восстановления full redundancy after the most severe failure that can be tolerated by the disk group.
1.1 Добавим один диск в группу:
SQL> ALTER DISKGROUP testkks1 ADD DISK 'ORCL:DISK3';
Diskgroup altered.
Смотрим результат:
Что мы тут видим:
Total_MB- увеличился на объём одного диска
Free_MB- увеличился на объём одного диска
Req_mir_free_MB- увеличился на объём одного диска
Шок контент: Usable_file_MB- не изменился. Как было 5042, так и осталось.
1.2 Удалим диск:
Вернулись туда откуда и пришли.
1.3 Добавим два диска в дисковую группу:
SQL> ALTER DISKGROUP testkks1 ADD DISK 'ORCL:DISK3','ORCL:DISK4' REBALANCE POWER 9 WAIT;
Diskgroup altered.
Смотрим результат:
Что мы тут видим:
Total_MB- увеличился на объём двух дисков
Free_MB- увеличился на объём двух дисков
Req_mir_free_MB- равен объему одного диска
Usable_file_MB- изменился, добавилась половина объёма одного диска
Добавим ещё один диск:
SQL> ALTER DISKGROUP testkks1 ADD DISK 'ORCL:DISK5' REBALANCE POWER 9 WAIT;
Diskgroup altered.
Total_MB- увеличился на объём одного диска
Free_MB- увеличился на объём одного диска
Req_mir_free_MB- равен объему одного диска (не изменился)
Usable_file_MB- изменился, добавилась половина объёма одного диска
Теперь сделаем заключение, о том, что:
Total_MB- общий объём, именно, сырого места
Free_MB- общий объём свободного, именно, сырого места
Req_mir_free_MB- равен объёму одного диска, если указано: normal избыточности, количество дисков больше или равно 3, и если не указывать Failgroup при создании дисковой группы индивидуально для дисков.
Из этого следует, что при normal избыточности (двойной) и количестве дисков 3 и более, Usable_file_MB будет равен:
Usable_file_MB=(Free_MB — Req_mir_free_MB)/2
Для 5 дисков:
Usable_file_MB=(25438-5119)/2= 10 159
Для 4 дисков:
Usable_file_MB=(20321-5119)/2=7 601
Для 3 дисков:
Usable_file_MB=(15204-5119)/2= 5 042
Для 2 дисков Usable_file_MB=(10136-0)/2= 5 068
Пограничный случай для 3х дисков показывает, что начиная с этого количества дисков, ASM начинает резервировать 1 диск, для восстановления full redundancy after the most severe failure that can be tolerated by the disk group.
Конфигурация 2: Дисковая группа из двух дисков с избыточностью Normal и её заполнение.
1.1 Исходное состояние:
Заполняем:
SQL> create tablespace kkstbs1 datafile '+TESTKKS1' size 5050M autoextend on next 10m;
Tablespace created.
Результат:
Расширим файл данных ещё на 10М:
SQL> alter database datafile '+TESTKKS1/kksdb/DATAFILE/KKSTBS1.256.1046190953' resize 5060M;
Database altered.
Результат:
Расширим ещё на 10М:
SQL> alter database datafile '+TESTKKS1/kksdb/DATAFILE/KKSTBS1.256.1046190953' resize 5070M;
alter database datafile '+TESTKKS1/kksdb/DATAFILE/KKSTBS1.256.1046190953' resize 5070M
*
ERROR at line 1:
ORA-01237: cannot extend datafile 5
ORA-01110: data file 5: '+TESTKKS1/KKSDB/DATAFILE/kkstbs1.256.1046190953'
ORA-17505: ksfdrsz:1 Failed to resize file to size 648960 blocks
ORA-15041: diskgroup "TESTKKS1" space exhausted
Не тут-то было.
На данном этапе, делаем два важных вывода, Free_MB это действительно сырое место, т.к. его значение в двух итерациях(1. Создание табличного пространства (Free_MB 30 и Usable_file 15) и расширение файла данных (Free_MB 10 и Usable_file 5)) в два раза (Normal избыточность) больше чем Usable_file_MB.
1.2 Добавляем диск:
SQL> ALTER DISKGROUP testkks1 ADD DISK 'ORCL:DISK3' REBALANCE POWER 9 WAIT;
Diskgroup altered.
Результат:
Теперь расширим файл данных на существенные 1024м:
SQL> alter database datafile '+TESTKKS1/kksdb/DATAFILE/KKSTBS1.256.1046190953' resize 6074M;
Database altered.
На данном этапе заключим, что Usable_file_MB ушел в минус за счет одного диска, который зарезервирован для восстановления full redundancy after the most severe failure that can be tolerated by the disk group, иначе получим ошибку ORA-15041, которая говорит о том, что закончилось место на дисковой группе. И заметим, что данные начали попадать на этот диск задолго до того, как Usable_file_MB стал отрицательным.
Очевидно, что далее заполнять дисковую группу бессмысленно, т.к. максимум мы можем уйти в минус, на данном этапе, это Usable_file_MB = -5119.
А теперь обратимся к документации:
REQUIRED_MIRROR_FREE_MB indicates the amount of space that must be available in a disk group to restore full redundancy after the worst failure that can be tolerated by the disk group without adding additional storage. This requirement ensures that there are sufficient failure groups to restore redundancy. Also, this worst failure refers to a permanent failure where the disks must be dropped, not the case where the disks go offline and then back online.
Согласно данному описанию, в текущей ситуации(Usable_file_MB в минусе, на диске, который должен быть резервным, лежит данных больше, чем положено), если мы внезапно потеряем один диск, то произойдёт что интересное.
Проверяем, теряем диск:
SQL> alter diskgroup testkks1 set attribute 'DISK_REPAIR_TIME'='10m';
Diskgroup altered.
——Здесь я сменил тип устройства с nvme на scsi (изменились названия Failgroup) т.к. нормального способа отключить nvme диск на виртуальной машине я не нашел ))) —-
NOTE: updating disk modes to 0x5 from 0x7 for disk 3 (DISK1) in group 2 (TESTKKS1): lflags 0x0
NOTE: disk 3 (DISK1) in group 2 (TESTKKS1) is offline for reads
NOTE: updating disk modes to 0x1 from 0x5 for disk 3 (DISK1) in group 2 (TESTKKS1): lflags 0x0
NOTE: disk 3 (DISK1) in group 2 (TESTKKS1) is offline for writes
Ребаланс ещё не запускался, с момента потери диска 10мин не прошло:
Попробуем расширить файл данных ещё на 1024М:
SQL> alter database datafile '+TESTKKS1/kksdb/DATAFILE/KKSTBS1.256.1046190953' resize 7098M;
Database altered.
Тут странность номер 1, хотя убитый диск “disk 3 (DISK1) in group 2 (TESTKKS1) is offline for writes”, его Free_MB уменьшился с 1012Мб до 332мб. Странность номер 2, максимальный Usable_file_MB = 5 042 в данной конфигурации, размер файла данных на момент удаления диска 6074Мб.
По прошествии ‘DISK_REPAIR_TIME’=’10m’ диск благополучно удалился:
Sun Jul 19 19:48:09 2020
SUCCESS: alter diskgroup TESTKKS1 drop disk DISK1 force /* ASM SERVER */
Но диск остался переименованным _DROPPED_0003_TESTKKS1.
Попытка провести ребеланс или добавить файл размером 10м неудачна:
ORA-15041: diskgroup "TESTKKS1" space exhausted
Sun Jul 19 19:48:12 2020
WARNING: Rebalance encountered ORA-15041; continuing
SQL> alter tablespace kkstbs1 add datafile '+TESTKKS1' size 10m;
alter tablespace kkstbs1 add datafile '+TESTKKS1' size 10m
*
ERROR at line 1:
ORA-01119: error in creating database file '+TESTKKS1'
ORA-17502: ksfdcre:4 Failed to create file +TESTKKS1
ORA-15041: diskgroup "TESTKKS1" space exhausted
Итого, на данный момент получилось, дисковая группа с normal избыточностью, из 3 дисков, превратилась в группу с двумя дисками.
При двух или трёх дисках, Usable_file_MB дисковой группы равен 5 042 Мб, при потере диска и нахождении Usable_file_MB в минусе, теряется избыточность тех данных, которые вызвали минус, т.к. сейчас размер табличного пространства 7098M.
Выведение ещё одного диска из строя приведёт к потере табличного пространства или дисковой группы.