Для начала приведу первоисточник, благодаря которому, проблема была локализована и устранена:
2. Finding the root cause of “CPU waits” using stack profiling
В первоисточнике вы можете подробнее ознакомится с механизмами и параметрами, которые будут упомянутs здесь, я же только опишу конечный результат, который получился у меня.
Описание проблемы: после того как бд переехала на сервер с 4мя сокетами, по достижению определённой нагрузки, резко вырастали ожидания log file sync и buffer busy wait.
Окружение: RHEL 7, Oracle 12.1.0.2 + BP, ASM 12.1.0.2 + BP
Как это выглядит:
AWR:
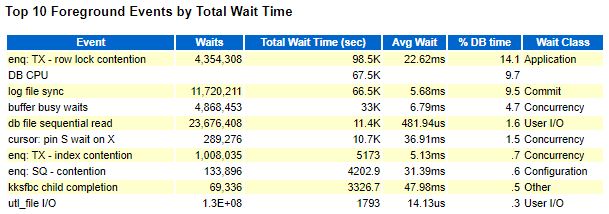
Lab128:

Промежутки времени для AWR и Lab128 взяты немного разные, поэтому есть разница в цифрах, но общей картины это не меняет, всё очень плохо.
1. Первым делом решено было бороться с log file sync(LFS).
Из ссылки 1 я узнаю про параметр _log_parallelism_max.
Критерии, по которым можно попробовать оценить, есть ли смыл в изменении его значения по умолчанию:
1. Ожидание log file sync гораздо выше(более чем в 2 раза) log file parallel write
Например, log file sync= 1мс, а log file parallel write=2мс и выше.
2. Оценить значении log file parallel write P3(Number of I/O requests) из v$active_session_history/dba_active_session_history в нагруженный и не нагруженный период. P3 должен изменяться, от 1 до _log_parallelism_max т.е. быть 2,3,4,5…
3. При повышении значения log file parallel write P3(Number of I/O requests), log file sync должен расти, но возможно не обязан.
4. Количество потоков CPU больше, либо равно 64.
5. Log File Parallel Writes Take Longer with a Higher CPU Count (Doc ID 1980199.1)
Я применил значение _log_parallelism_max=2
Результат:
AWR:
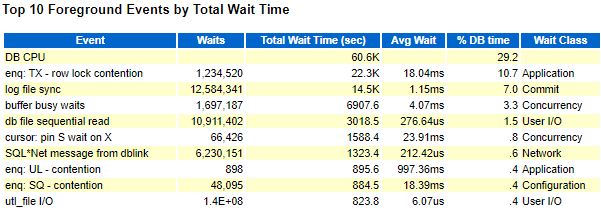
log file sync снизился с 5.68мс до 1.15мс(по AWR), казалось бы победа, но нет, присутствует ожидание buffer busy wait, которое оказывает сильное влияние на работу приложения, да и само значение log file sync всё ещё выше, чем на старом сервере, даже после улучшения.
2. Здесь переходим ко второй части.
Ожидания buffer busy wait с работой приложения никак не связано, профиль нагрузки практически не менялся. Kоличественные характеристики полезной работы бд: dml выполненных в секунду, количество коммитов в секунду, LIO в секунду в целом выросли на 5%-10% и после переезда на 4 сокета, buffer busy wait раскрылся во всей красе, опять таки только по достижению определённой нагрузки(превышение на 5%-10%), если её не превышать, то всё хорошо.
Всё хорошо — это означает, что ожидания buffer busy wait стремятся к нулю, а log file sync значительно меньше 1мс (0.3-0.6мс) для работы под нужной нагрузкой.
Вышеописанное должно привести на мысль, что что-то не так с железом, либо проблема на уровне OS. Здесь на помощь приходит вторая ссылка, из которой становится понятно, что вероятно дело в kernel.numa_balancing. И действительно, если поискать на MOS используя kernel.numa_balancing, то получим:
- Requirements for Installing Oracle Database 19c on OL7 or RHEL7 64-bit (x86-64) (Doc ID 2551169.1)
- (EX39) NUMA-enabled database servers experience continuously high load or reduced performance after updating to Exadata 12.2.1.1.0 or higher. (Doc ID 2319324.1)
А также из общедоступных источников: Optimal Configuration of Memory System
Откуда следует вывод, что без kernel.numa_balancing=0 никуда. И действительно, после применения данного параметра, производительность бд значительно выросла:

В итоге, конфигурация имеет значение _log_parallelism_max=2 на уровне бд и kernel.numa_balancing=0 на уровне ОС.
Также эксперимент был проведён на Solaris Sparc:
Solaris Sparc : 11.4+patch
Oracle 12.1.0.2 + BP
ASM 19.7
И _log_parallelism_max=2 VS_log_parallelism_max=1:

Нагрузка тут уже в 3 раза выше, чем на Linux, а снижение LFS c 0.77 мс до 0.60 мс дало прирост быстродействия на стороне приложения до 30%.
Также _log_parallelism_max=1 снизил потребление ЦПУ на 7%.
Выводов нет, делайте их сами, а использование скрытых параметров должно быть обоснованным и обдуманным решением.
