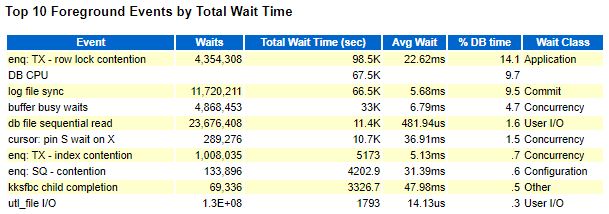
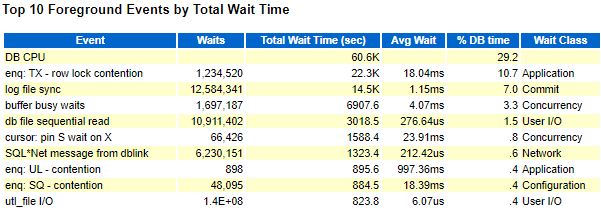
Окружение:
OS: OEL 7.8
DB: 12.1.0.2.190716 BP, 2. 19.7.0.0.200414 RU
При выполнений пакетных заданий и не только было замечено интересное — фрагментация таблиц, где казалось бы её не должно быть(или должно?).
Для проверки влияния был составлен тест из 3 циклов:
1 цикл — главный.
2 цикл находится внутри цикла 1, выполняет вставку.
3 цикл находится внутри цикла 1, выполняет удаление.
Количество проходов циклов 2 и 3 одинаково и задаётся при старте, циклы выполняются друг за другом, commit выполняется после каждой удалённой или вставленной строки.
Тест проводится с участим трёх таблиц(KKS$FRAG_512B, KKS$FRAG_1024B, KKS$FRAG_2048B), в которых длина вставляемой строки заранее известна, это 512байт, 1024байт и 2048байта. Размер сегмента берётся из dba_segments.
Для таблиц KKS$FRAG_512B, KKS$FRAG_1024B, KKS$FRAG_2048B было выполнено:
| Количество циклов | Количество операций вставок и удалений в каждом цикле |
| 303 | 2003 |
| 606 | 1006 |
| 606 | 706 |
| 606 | 506 |
| 606 | 106 |
- Результат для KKS$FRAG_512B:
| 12.1.0.2.190716 BP, занято байт в таблице KKS$FRAG_512B | 33554432 | ||
| 12.1.0.2.190716 BP, занято блоков в таблице KKS$FRAG_512B | 4096 | ||
| 19.7.0.0.200414 RU, занято байт в таблице KKS$FRAG_512B | 7340032 | ||
| 19.7.0.0.200414 RU, занято блоков в таблице KKS$FRAG_512B | 896 |
Различие в размере сегмента составляет 4,5 раза.
2. Результат для KKS$FRAG_1024B:
| 12.1.0.2.190716 BP, занято байт в таблице KKS$FRAG_1024B | 33554432 | ||
| 12.1.0.2.190716 BP, занято блоков в таблице KKS$FRAG_1024B | 4096 | ||
| 19.7.0.0.200414 RU, занято байт в таблице KKS$FRAG_1024B | 9437184 | ||
| 19.7.0.0.200414 RU, занято блоков в таблице KKS$FRAG_1024B | 1152 |
Отличие скромнее, но оно по прежнему существенно — в 3,5 раза.
3. Результат для KKS$FRAG_2048B:
| 12.1.0.2.190716 BP, занято байт в таблице KKS$FRAG_2048B | 19922944 | ||
| 12.1.0.2.190716 BP, занято блоков в таблице KKS$FRAG_2048B | 2432 | ||
| 19.7.0.0.200414 RU, занято байт в таблице KKS$FRAG_2048B | 16777216 | ||
| 19.7.0.0.200414 RU, занято блоков в таблице KKS$FRAG_2048B | 2048 |
Разница не велика, но она есть: 1,18 раза
4. Другой профиль нагрузки для KKS$FRAG_512B.
| Количество циклов | Количество операций вставок и удалений в каждом цикле |
| 2002 | 1002 |
| 12.1.0.2.190716 BP, занято байт в таблице KKS$FRAG_512B | 46137344 | ||
| 12.1.0.2.190716 BP, занято блоков в таблице KKS$FRAG_512B | 5632 | ||
| 19.7.0.0.200414 RU, занято байт в таблице KKS$FRAG_512B | 720896 | ||
| 19.7.0.0.200414 RU, занято блоков в таблице KKS$FRAG_512B | 88 |
Разница: в 64 раза
5. Другой профиль нагрузки для KKS$FRAG_1024B.
| Количество циклов | Количество операций вставок и удалений в каждом цикле |
| 2002 | 1002 |
Результат:
| 12.1.0.2.190716 BP, занято байт в таблице KKS$FRAG_1024B | 262144 | ||
| 12.1.0.2.190716 BP, занято блоков в таблице KKS$FRAG_1024B | 32 | ||
| 19.7.0.0.200414 RU, занято байт в таблице KKS$FRAG_1024B | 196608 | ||
| 19.7.0.0.200414 RU, занято блоков в таблице KKS$FRAG_1024B | 24 |
Разница: в 1.3 раза
Исходя из результатов тестов можно сделать вывод: при переходе на версию 19с, рост бд возможно замедлиться при одинаковой нагрузке. Самое время понять, что приводит к такому различию размеров таблиц.