Many probably know that frequent commits are bad and slow, but how bad and how slow is not clear, and this small test is designed to demonstrate the impact of this event.
I’ll note right away that commits should be made exactly when the business process requires it, or when there is any other significant reason, rather than just ‘in case.’
Test environment:
Oracle 19.23
OS: OEL 8.5 4.18.0-513.24.1.el8_9.x86_64
RAM: 128GB
CPU: AMD Threadripper 1920x
Disks:
Disk group for data files: +ORADATA: SATA SSD GeIL R3 512GB
Disk group for redo logs: +ADATAD1: XPG GAMMIX S11 Pro PCI E 3.0 x4
Disk group for archive logs: +ARCHLOG: SATA SSD GeIL R3 512GB
+ORADATA and +ARCHLOG are located on the same physical disk SATA SSD GeIL R3 512GB.
The code that will act as the load (intensive business process activity):
Variant 1:
declare
v_loop number;
v_seq number;
v_text varchar2(3000);
v_rtext varchar2(3000);
begin
execute immediate 'truncate table t1';
dbms_output.put_line('Start: '||to_char(sysdate,'dd.mm.yyyy hh24:mi:ss'));
dbms_workload_repository.create_snapshot;
v_loop:=1;
select dbms_random.string(opt => 'X',len => 3000) into v_rtext from dual;
while v_loop<5000001
loop
v_seq:=t1_seq.nextval;
insert into t1(id,text) values(v_seq,v_rtext);
commit write wait;
select t1.text into v_text from t1 where id=v_seq;
update t1 set t1.text='update' where id=v_seq;
commit write wait;
delete from t1 where id=v_seq;
commit write wait;
v_loop:=v_loop+1;
end loop;
dbms_workload_repository.create_snapshot;
dbms_output.put_line('End: '||to_char(sysdate,'dd.mm.yyyy hh24:mi:ss'));
end;
Variant 2:
declare
v_loop number;
v_seq number;
v_text varchar2(3000);
v_rtext varchar2(3000);
begin
execute immediate 'truncate table t1';
dbms_output.put_line('Start: '||to_char(sysdate,'dd.mm.yyyy hh24:mi:ss'));
dbms_workload_repository.create_snapshot;
v_loop:=1;
select dbms_random.string(opt => 'X',len => 3000) into v_rtext from dual;
while v_loop<5000001
loop
v_seq:=t1_seq.nextval;
insert into t1(id,text) values(v_seq,v_rtext);
select t1.text into v_text from t1 where id=v_seq;
update t1 set t1.text='update' where id=v_seq;
delete from t1 where id=v_seq;
commit write wait;
v_loop:=v_loop+1;
end loop;
dbms_workload_repository.create_snapshot;
dbms_output.put_line('End: '||to_char(sysdate,'dd.mm.yyyy hh24:mi:ss'));
end;
The difference between the first and second options is that the first option has 3 commits within the loop, while the second has 1 commit within the loop. Also, the ‘commit write wait’ construct is chosen to avoid PL/SQL optimization, as this commit variant is used if the code is not written in PL/SQL.
Variant 1 took 23 minutes and 6 seconds (1386 seconds) to complete.
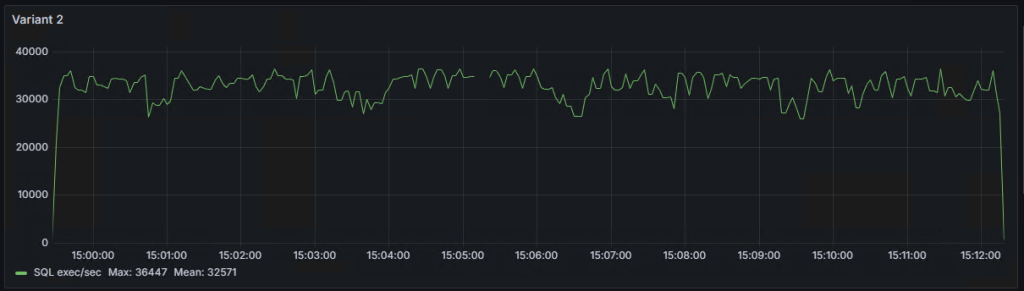
Variant 2 took 12 minutes and 51 seconds (771 seconds) to complete.
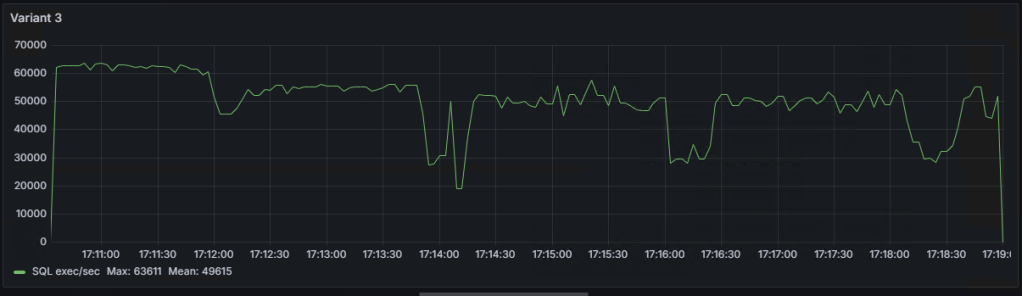
Variant 3 (commit executed only at the end of the loop) took 503 seconds, but it’s not considered for evaluation.
So, Variant 2 is nearly twice as fast.
Reasons why Variant 1 took longer:
Further calculations are done with a certain margin of error, and it is assumed that all statistics relate only to the tasks being performed.
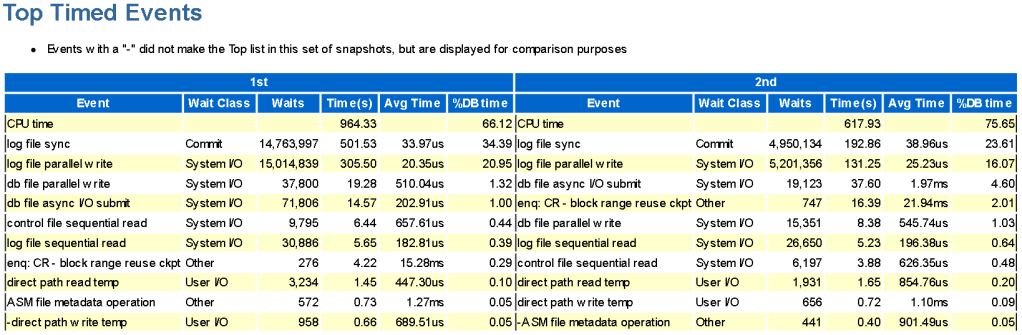
Variant 1 took 501 seconds for log file sync (lfs) out of 1386 seconds, while variant 2 took 192 seconds for log file sync (lfs) out of 771 seconds. By subtracting 501 from 1386, we get 885 seconds. Mathematically excluding all intermediate commits in the loop from variant 1, it still takes more time than variant 2, with 885 seconds versus 771 seconds.
Graph of the number of SQL statement executions per second for ‘Variant 1,’ ‘Variant 2,’ and ‘Variant 3’:
As seen on the graphs, there are some ‘dips,’ the explanations for which I will try to provide in the following note.
Многие наверно знают, что частые коммиты — это плохо и медленно, но насколько плохо и насколько медленно, не понятно и данный маленький тест призван показать влияние этого события.
Сразу отмечу, что выполнять коммит нужно ровно тогда, когда этого требует бизнес-процесс, либо имеется любая другая веская причина, а не просто “на всякий случай”.
Тестовый стенд:
Oracle 19.23
OS: OEL 8.5 4.18.0-513.24.1.el8_9.x86_64
RAM: 128GB
CPU: AMD Threadripper 1920x
Диски:
Дисковая группа для датафайлов: +ORADATA: SATA SSD GeIL R3 512GB
Дисковая группа для редологов: +ADATAD1: XPG GAMMIX S11 Pro PCI E 3.0 х4
Дисковая группа для архивных логов: +ARCHLOG: SATA SSD GeIL R3 512GB
+ORADATA и +ARCHLOG расположены на одном физическом диске SATA SSD GeIL R3 512GB.
Код, который будет выступать в виде нагрузки (бурной деятельности бизнес-процессов):
Вариант номер 1:
declare
v_loop number;
v_seq number;
v_text varchar2(3000);
v_rtext varchar2(3000);
begin
execute immediate 'truncate table t1';
dbms_output.put_line('Start: '||to_char(sysdate,'dd.mm.yyyy hh24:mi:ss'));
dbms_workload_repository.create_snapshot;
v_loop:=1;
select dbms_random.string(opt => 'X',len => 3000) into v_rtext from dual;
while v_loop<5000001
loop
v_seq:=t1_seq.nextval;
insert into t1(id,text) values(v_seq,v_rtext);
commit write wait;
select t1.text into v_text from t1 where id=v_seq;
update t1 set t1.text='update' where id=v_seq;
commit write wait;
delete from t1 where id=v_seq;
commit write wait;
v_loop:=v_loop+1;
end loop;
dbms_workload_repository.create_snapshot;
dbms_output.put_line('End: '||to_char(sysdate,'dd.mm.yyyy hh24:mi:ss'));
end;
Вариант номер 2:
declare
v_loop number;
v_seq number;
v_text varchar2(3000);
v_rtext varchar2(3000);
begin
execute immediate 'truncate table t1';
dbms_output.put_line('Start: '||to_char(sysdate,'dd.mm.yyyy hh24:mi:ss'));
dbms_workload_repository.create_snapshot;
v_loop:=1;
select dbms_random.string(opt => 'X',len => 3000) into v_rtext from dual;
while v_loop<5000001
loop
v_seq:=t1_seq.nextval;
insert into t1(id,text) values(v_seq,v_rtext);
select t1.text into v_text from t1 where id=v_seq;
update t1 set t1.text='update' where id=v_seq;
delete from t1 where id=v_seq;
commit write wait;
v_loop:=v_loop+1;
end loop;
dbms_workload_repository.create_snapshot;
dbms_output.put_line('End: '||to_char(sysdate,'dd.mm.yyyy hh24:mi:ss'));
end;
Отличие первого и второго варианта в том, что первый вариант имеет 3 коммита в цикле, а второй 1 коммит в цикле. Также, конструкция commit write wait выбрана для того, чтобы избежать оптимизации PL/SQL, т.к. данный вариант коммита применяется если код написан не на PL/SQL.
Вариант 1, выполнился за 23 минуты и 6 секунд(1386 секунд)
Вариант 2, выполнился за 12 минут и 51 секунду(771 секунд).
В не зачёта: Вариант 3(коммит выполняется только по окончанию цикла), выполнился за 503 секунды.
Т.е. вариант 2 быстрее почти в 2 раза.
На что вариант 1 потратил время(почему он медленнее):
Далее расчеты делаются с определённой погрешностью и предполагается, что все статистики относятся только к выполняемым задачам.
Вариант 1 из 1386 секунд, потратил на log file sync(lfs) 501 сек, а вариант 2 из 771 секунд, потратил на log file sync(lfs) 192 сек. Отняв от 1386, 501, получим 885 сек, т.е. математически исключим все промежуточные коммиты в цикле из варианта 1, всё равно вариант 1 затрачивает времени больше, чем вариант 2, 885сек против 771сек.
График количества выполнений SQL выражений в секунду для “вариант 1”,“вариант 2” и “вариант 3”:
Как видно на графиках, есть некие “провалы”, объяснения которым я попробую дать в следующей заметке.
After installing DBRU19.19 on 19.9, one table started to grow linearly. The table is a buffer, with insertion and almost immediate deletion. The table consistently holds around 1000 rows, but its volume increases every day. Upon searching on Oracle Support, Bug 30265523 was found — blocks are not marked as free in Automatic Segment Space Management (ASSM) after deletion — 12.2 and later (Doc ID 30265523.8).
After dumping the first level bitmap block of free space in the extent, I see the following picture:
We observe rejection code 3, and all blocks are marked as FULL. This fully coincides with the description of the bug, which supposedly has been fixed. If we dump a block with data, there will be only one row in it, marked as deleted (—HDFL—). It is worth noting that the problematic table has several varchar2(4000) fields, out of which always two fields are filled up to the brim, and sometimes three fields, while the rest are always null. The table does not have any chained and migrated rows.
Further experiments have shown that:
Disabling or setting _enable_rejection_cache = false does not help or worsens the situation.
Disabling _assm_segment_repair_bg=false does not help either.
The combination of _enable_rejection_cache = false and _fix_control=’32075777:ON’ does not help either.
The potential solution (a workaround) may only be setting one parameter: _fix_control=’32075777:ON’.
Setting _fix_control=’32075777:ON’ has helped maintain the table within normal size limits. Under constant load, the table stopped growing. With the same load, in 19.9 the table had a size of a couple of hundred megabytes, while in 19.19 with _fix_control=’32075777:ON’, the growth stopped at around 1GB. Also, upon setting _fix_control=’32075777:ON’, a non-zero metric ASSM_bg_slave_fix_state appeared, which apparently increases after fixing the status of blocks in the bitmap, and x$ktsp_repair_list started to fill up (I assume this displays a list of segments on which the segment repair mechanism has been activated). I have opened an SR.
Overall, how has the operation of ASSM changed? Before 06/21, the database was running on DBRU 19.9, and after 6/20, on 19.19.
Issue: There is a dead transaction rolling back at a rate of 1-2 blocks per second, blocking the execution of update/delete/insert with a wait for transaction (event#=1074, name=transaction). Oracle Version: 19.21.
Since transaction rollback can take a considerable amount of time, it’s essential to assist this process. To do this, you need to drop the object associated with the transaction causing the slow rollback. How to determine the object that needs to be dropped? This might not be straightforward because the transaction could involve multiple tables. In my case, I enabled tracing 10046 for the SMON process, in which there were waits like ‘enq: CR — block range reuse ckpt’ obj#=MyProblematicObject. Additionally, I dumped the header of the undo segment (alter system dump undo header «_SegmentName») and the undo blocks associated with the transaction (alter system dump undo block «_SegmentName» XID number_USN number_SLT number_SEQ).
Where do we get what?
USN, SLT,SEQ- from select * from v$fast_start_transactions
_SegmentName- from Select * from v$rollname where usn = USN
In the dump of blocks associated with the transaction, there is a lot of this:
There are suspicions that KTSL stands for Kernel Transaction Segment LOB, but this is not certain. In the dump of the undo header and in the dump of blocks associated with the transaction, there should be a connection as follows: in the undo segment header in the TRN TBL section, the cmt column has a value of 0, and in the dba column at the same level, there are coordinates of the block. Dumping this block, we will enter the UBA, which is associated with ‘alter system dump undo block «_SegmentName» XID number_USN number_SLT number_SEQ’
After analyzing a lot of text, I select the necessary object and drop it.))
alter system set "_smu_debug_mode"=1024;
oradebug setospid <ospid of SMON process>
oradebug event 10513 trace name context forever, level 2
drop table owner.table purge;
purge recyclebin;
oradebug event 10513 trace name context off
alter system set "_smu_debug_mode"=0;
Also, I used fast_start_parallel_rollback=false; (changing this parameter can stop the rollback process, either the instance needs to be restarted or attempt to revive SMON)
Useful notes:
Database Hangs Because SMON Is Taking 100% CPU Doing Transaction Recovery (Doc ID 414242.1)
IF: Transaction Recovery or Rollback of Dead Transactions (Doc ID 1951738.1)
I would like to highlight:
Bug 11790175 — SMON spins in rollback of LOB due to double allocated block like bug 11814891 (Doc ID 11790175.8)
This is an ancient bug, the description of which in my case coincides only on two criteria: Slow rollback Problematic object is LOB.
UNDO and REDO, a complex topic… perhaps there is a simpler method.
Проблема: Имеется мёртвая(Dead) транзакция которая откатывается со скоростью 1-2 блока в секунду, которая блокирует выполнение update/delete/insert с ожиданием transaction(event#=1074, name=transaction). Версия Oracle: 19.21.
Т.к. откат транзакции может занять значительное время, самое время как то помочь этому процессу. Для этого, нужно дропнуть обьект, с которым связана транзакция из-за которого откат идёт очень медленно. Как определить объект который нужно дропунуть? Вот тут всё может быть не однозначно, т.к. в транзакции может быть замешано N таблиц. В моём случае я включил трассировку 10046 для процесса SMON, в которой были ожидания вида ‘enq: CR — block range reuse ckpt’ obj#=МойПроблемныйОбъект, далее я сдампил ещё заголовок undo сегмента(alter system dump undo header «_ИмяСегмента») и ундо блоки связанные с транзакцией (alter system dump undo block «_ИмяСегмента» XID номер_USN номер_SLT номер_SEQ).
Откуда, что берём:
USN, SLT,SEQ- из select * from v$fast_start_transactions
_ИмяСегмента- из Select * from v$rollname where usn = USN
В дампе блоков связанных с транзакцией кучи вот такого:
Есть подозрения, что KTSL это -Kernel Transaction Segment LOB, но это не точно. В дампе заголовка ундо и в дампе блоков связанных с транзакцией, должна быть связь в виде: в заголовке ундо сегмента в разделе TRN TBL, в колонке cmt есть значение 0, а в колонке dba на этом же уровне, имеются координаты блока, сдампив который, мы попадём в UBA, который связан с alter system dump undo block «_ИмяСегмента» XID номер_USN номер_SLT номер_SEQ.
Нужно взять книжку Oracle Core от Jonathan Lewis, и ещё раз перечитать....
Проанализировав кучу текста, выбираем нужный обьект и дропаем))):
alter system set "_smu_debug_mode"=1024;
oradebug setospid <ospid of SMON process>
oradebug event 10513 trace name context forever, level 2
drop table owner.table purge;
purge recyclebin;
oradebug event 10513 trace name context off
alter system set "_smu_debug_mode"=0;
Так же, я использовал fast_start_parallel_rolback=false;(переключение этого параметра может остановить процесс отката, тут либо инстанс перезапускать, либо пытаться оживить SMON).
Откат транзакции ускорится в сотни раз. Как завершится, создаём таблицу по новой.
Полезные ноты:
Database Hangs Because SMON Is Taking 100% CPU Doing Transaction Recovery (Doc ID 414242.1)
IF: Transaction Recovery or Rollback of Dead Transactions (Doc ID 1951738.1)
Отдельно хочу отметить:
Bug 11790175 — SMON spins in rollback of LOB due to double allocated block like bug 11814891 (Doc ID 11790175.8)
Это древний баг, описание которого в моём случае совпадает только по двум критериям:
Медленный откат
Проблемный объект: LOB
UNDO и REDO, тяжелая тема… возможно есть метод и попроще.
Коротенькая заметка про очередные грабли, всплывшие где-то с 19.16, но так-же существуют в плоть до 19.22.
Дано:
Oracle: 19.22
OS: Oracle Linux Server release 8.3
Kernel: 5.4.17-2011.7.4.el8uek.x86_64
При старте БД наблюдаем в алерт логе такую картину:
Starting background process VKTM
Errors in file /oracle/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_vktm_61290.trc (incident=146927):
ORA-00800: soft external error, arguments: [Set Priority Failed], [VKTM], [Check traces and OS configuration], [Check Oracle document and MOS notes], []
Incident details in: /oracle/app/oracle/diag/rdbms/orcl/orcl/incident/incdir_146927/orcl_vktm_61290_i146927.trc
Error attempting to elevate VKTM's priority: no further priority changes will be attempted for this process
Starting background process LGWR
Errors in file /oracle/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_lgwr_61456.trc (incident=147055):
ORA-00800: soft external error, arguments: [Set Priority Failed], [LGWR], [Check traces and OS configuration], [Check Oracle document and MOS notes], []
Incident details in: /oracle/app/oracle/diag/rdbms/orcl/orcl/incident/incdir_147055/orcl_lgwr_61456_i147055.trc
Starting background process DBW0
Errors in file /oracle/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_dbw0_61444.trc (incident=147039):
ORA-00800: soft external error, arguments: [Set Priority Failed], [DBW0], [Check traces and OS configuration], [Check Oracle document and MOS notes], []
Incident details in: /oracle/app/oracle/diag/rdbms/orcl/orcl/incident/incdir_147039/orcl_dbw0_61444_i147039.trc
Просмотрев трейсы, находим много общего, а именно:
Error Info: Category(-2), Opname(skgdism_send), Loc(sp.c:setpr:0), ErrMsg(Operation not permitted) Dism(128)
Если пойти на MOS то можно найти ноту ORA-00800: soft external error, arguments: [Set Priority Failed], [VKTM] (Doc ID 2931494.1), которая, как по мне, ведёт в тупик(если конечно у вас на $ORACLE_HOME/bin/oradism установлены верные разрешения root:oinstall 4750), особенно если у вас 19.22.
Я же просто установил cgroup_disable=cpu в grub.
vi /etc/default/grub. Добавляем cgroup_disable=cpu в секцию GRUB_CMDLINE_LINUX.
Далее выполнить:
Для легаси BIOS: grub2-mkconfig —output=/boot/grub2/grub.cfg
Для UEFI: grub2-mkconfig —output=/boot/efi/EFI/redhat/grub.cfg.
[root@perfdbhost ~]# grub2-mkconfig --output=/boot/grub2/grub.cfg
Generating grub configuration file ...
device-mapper: reload ioctl on osprober-linux-nvme0n4p1 (252:2) failed: Device or resource busy
Command failed.
device-mapper: reload ioctl on osprober-linux-nvme0n5p1 (252:2) failed: Device or resource busy
Command failed.
Done
Перезагружаем хост.
P.S. В дальнейшем можно убрать cgroup_disable=cpu, процессы не получают(??) ошибок Set Priority Failed.
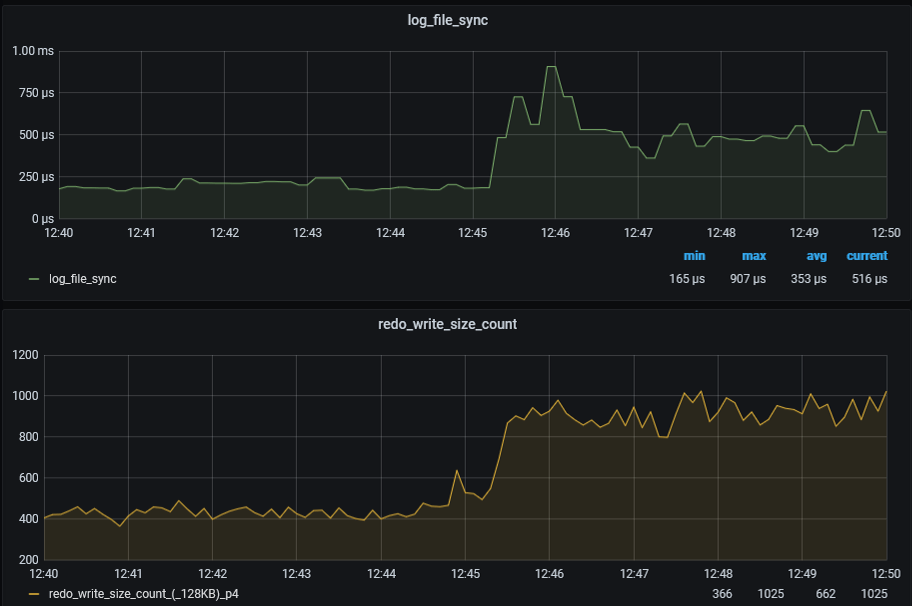
In this note, I will visually demonstrate how the transition of lgwr from poll->post to post/wait mode can look like.
Investigate time when it happened by using trace file of lgwr process:
*** 2023-02-16T12:45:09.010167+06:00
Log file sync switching to post/wait
Current approximate redo synch write rate is 10286 per sec
Fig.1Fig.2
Figure 1 shows that the transition of lgwr from poll->post to post/wait mode led to a doubling of the log file sync wait time, from 250 microseconds to 500 microseconds. Additionally, the number of redo blocks written in 128KB doubled. Although not visible in the graphs, there is also a decrease in the number of redo blocks written that are much smaller than 128KB (4, 8, 16, 32KB, etc).
Figure 2 shows how the number of log file parallel write waits (oracledb_event_p3_log_file_parallel_write_p2) has changed. The number of waits has decreased by half, but the duration of a single log file parallel write wait (oracledb_event_p2_log_file_parallel_write_p2) has increased by an average of 50%, from 50 microseconds to 75 microseconds.
It looks like some sort of ferry mode where fewer operations are performed with larger block sizes, resulting in a 2x reduction in response time. This behavior is subject to change according to the algorithm and database parameters associated with the adaptive operation of LGWR.
You can read more here:
Adaptive Switching Between Log Write Methods can Cause ‘log file sync’ Waits (Doc ID 1462942.1)
В данной заметке показано наглядно, как может выглядеть переход lgwr от poll->post к режиму post/wait.
Смотрим в трейс файл процесса lgwr, находим там:
*** 2023-02-16T12:45:09.010167+06:00
Log file sync switching to post/wait
Current approximate redo synch write rate is 10286 per sec
Идём в графану и смотрим визуализацию этого события:
Рис1.
Рис2.
На рисунке 1 показано, что переход lgwr от poll->post к режиму post/wait привёл к увеличению ожидания log file sync в 2 раза, с 250мксек до 500мксек, также, увеличилось количество записи редо блоком в 128KB в два раза. На графики этого не видно, но также имеется снижение количества записи редо блоком гораздо меньшим чем 128KB(4,8,16,32KB etc).
На рисунке 2 показано, как изменилось количество ожиданий log file parallel write(oracledb_event_p3_log_file_parallel_write_p2). Количество ожиданий уменьшилось в два раза, в тоже время длительность одного ожидания log file parallel write(oracledb_event_p2_log_file_parallel_write_p2) увеличилось, в среднем на 50%, с 50мксек до 75мксек.
Выглядит как какой-то челночный режим, выполнить меньше операций большим размером блока, что даёт снижение отклика в 2 раза. Данное поведение меняется согласно алгоритму и параметрам базы данных связанных с адаптивной работы LGWR.
Подробнее можно почитать тут:
Adaptive Switching Between Log Write Methods can Cause ‘log file sync’ Waits (Doc ID 1462942.1)
В больших база данных, размеры которых идут на десятки, а то и сотни ТБ, и в зависимости от политики резервного копирования, могут образоваться сотни тысяч backup piece. При таком количестве backup piece задачи по удалению из rman каталога старых бэкапов, особенно инициированные не в ручную, а выполняемые по регламенту из какого либо софта MML , могут не успеть за отведённое время удалить необходимый перечень записей из контрольного файла и rman catalog. Это приведёт к накоплению устаревших записей о бэкапах как в контрольном файле, так и в rman каталоге.
Создание данных индексов позволят ускорить удаление записей из rman каталога в 4 раза:
create index BDF_DBINC_KEY_IX1 on BDF(Dbinc_Key,CKP_SCN)
create index BRL_DBINC_KEY_IX1 on BRL(Dbinc_Key,Low_Scn)
create index CDF_DBINC_KEY_IX1 on CDF(Dbinc_Key,Ckp_Scn)
create index ROUT_KEY_IX1 on ROUT(DB_KEY,Site_Key,Rout_Skey)
create index bp_ix1 on bp(DB_KEY,handle);
Так же, если в бд, откуда делаются бэкапы, при выполнении задач по удалению старых записей о бэкапах, присутствует ожидание “recovery area: computing obsolete files”, то вам следует выполнить/проверить реакцию бд на ALTER SYSTEM SET db_recovery_file_dest=» SCOPE=BOTH; Если конечно, оно, db_recovery_file_dest, вам ненужно.
upd. 25.03.2025, данная статья устарела, но полезна для общего развития, т.к. здесь была положена идея(в 2021г), которая преобразовалась в kPerf for Oracle
—————————————————————————————————————
Контроль стабильности работы бд требует мониторинга и понимания метрик этого мониторинга. В связи с этим я написал свой небольшой снапер метрик бд и вложил в него ‘своё’ восприятие этих метрик для своих нужд, но возможно общая идея будит интересна ещё кому ни будь.
Мониторинг состоит из нескольких компонентов:
Набор таблиц
Задание по расписанию для заполнения таблиц из пункта 1
Получение данных из таблиц пункта 1 и передача этих данных.
Grafana
Prometheus
OracleDB exporter
Инструкция не содержит пошаговой настройки всех компонентов, а только показывает, как собирается статистика в бд и как обрабатывается.
Набор таблиц.
1.1
CREATE SEQUENCE system.kks$sys_wait_event_sequence
MINVALUE 1
MAXVALUE 999999999999999999999999999
START WITH 1
INCREMENT BY 1
CACHE 20;
create table system.kks$system_wait_event(
wait_class varchar2(256),
TOTAL_WAITS_sum number,
TIME_WAITED_MICRO_sum number,
snap_time date default sysdate,
snap_id number
)
tablespace sysaux;
create index SYSTEM.snap_time_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT (snap_time) tablespace sysaux;
create index SYSTEM.wait_class_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT (wait_class) tablespace sysaux;
create index SYSTEM.snap_id_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT (snap_id) tablespace sysaux;
1.2
CREATE SEQUENCE system.kks$sys_wait_event_sequence_p1
MINVALUE 1
MAXVALUE 999999999999999999999999999
START WITH 1
INCREMENT BY 1
CACHE 20;
create table system.kks$system_wait_event_p1(
wait_event varchar2(256),
TOTAL_WAITS_sum number,
TIME_WAITED_MICRO_sum number,
snap_time date default sysdate,
snap_id number
)
tablespace sysaux;
create index SYSTEM.snap_time_p1_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT_p1 (snap_time) tablespace sysaux;
create index SYSTEM.wait_event_p1_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT_p1 (wait_event) tablespace sysaux;
create index SYSTEM.snap_p1_id_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT_p1 (snap_id) tablespace sysaux;
1.3
CREATE SEQUENCE system.kks$sys_wait_event_sequence_p2
MINVALUE 1
MAXVALUE 999999999999999999999999999
START WITH 1
INCREMENT BY 1
CACHE 20;
create table system.kks$system_wait_event_p2(
wait_event varchar2(256),
TOTAL_WAITS_sum number,
TIME_WAITED_MICRO_sum number,
snap_time date default sysdate,
snap_id number
)
tablespace sysaux;
create index SYSTEM.snap_time_p2_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT_p2 (snap_time) tablespace sysaux;
create index SYSTEM.wait_event_p2_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT_p2 (wait_event) tablespace sysaux;
create index SYSTEM.snap_p2_id_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT_p2 (snap_id) tablespace sysaux;
2. Задание по расписанию для заполнения таблиц из пункта 1
2.1
Заполняем таблицу из пункта 1.1. Делаем снапшот суммарного количества ожиданий по каждому классу ожиданий(WAIT_CLASS) и суммарного количества времени отведённого для каждого класса ожиданий(WAIT_CLASS), устаревшие данные удалям.
declare
seqno number;
begin
select system.kks$sys_wait_event_sequence.nextval into seqno from dual;
insert into system.kks$system_wait_event(wait_class,total_waits_sum,time_waited_micro_sum,snap_id)
select w.WAIT_CLASS,sum(w.TOTAL_WAITS) totalwaits,sum(w.TIME_WAITED_MICRO) mcsec,seqno from v$system_event w
where w.WAIT_CLASS!='Idle'
group by w.WAIT_CLASS;
insert into system.kks$system_wait_event(wait_class,time_waited_micro_sum,snap_id)
select o.STAT_NAME,o.VALUE,seqno from V$SYS_TIME_MODEL o where o.STAT_NAME='DB CPU';
commit;
delete from system.kks$system_wait_event p1 where p1.snap_time<=sysdate-30/24/60;
commit;
end;
2.2
Заполняем таблицу из пункта 1.2. Делаем снапшот суммарного количества ожиданий по каждому ожиданию(EVENT) и суммарного количества времени отведённого для каждого ожидания(EVENT), устаревшие данные удалям.
declare
seqno number;
begin
select system.kks$sys_wait_event_sequence_p1.nextval into seqno from dual;
insert into system.kks$system_wait_event_p1(wait_event,total_waits_sum,time_waited_micro_sum,snap_id)
select w.EVENT,sum(w.TOTAL_WAITS) totalwaits,sum(w.TIME_WAITED_MICRO) mcsec,seqno from v$system_event w
where w.WAIT_CLASS!='Idle' and w.EVENT!='SQL*Net message to client'
group by w.EVENT;
insert into system.kks$system_wait_event_p1(wait_event,time_waited_micro_sum,snap_id)
select o.STAT_NAME,o.VALUE,seqno from V$SYS_TIME_MODEL o where o.STAT_NAME='DB CPU';
commit;
delete from system.kks$system_wait_event_p1 p1 where p1.snap_time<=sysdate-30/24/60;
commit;
end;
2.3
Заполняем таблицу из пункта 1.3. Делаем снапшот суммарного количества ожиданий по каждому ожиданию(EVENT) и суммарного количества времени отведённого для каждого ожидания(EVENT), устаревшие данные удалям.
declare
seqno number;
begin
select system.kks$sys_wait_event_sequence_p2.nextval into seqno from dual;
insert into system.kks$system_wait_event_p2(wait_event,total_waits_sum,time_waited_micro_sum,snap_id)
select w.EVENT,sum(w.TOTAL_WAITS) totalwaits,sum(w.TIME_WAITED_MICRO) mcsec,seqno from v$system_event w
where w.WAIT_CLASS!='Idle' and w.EVENT!='SQL*Net message to client'
group by w.EVENT;
commit;
delete from system.kks$system_wait_event_p2 p1 where p1.snap_time<=sysdate-30/24/60;
commit;
end;
Я заполняю эти таблицы каждые 5сек. Возможно 2.3 избыточен, т.к. почти такие же данные есть в 2.2. Но тут кроется ‘моя’ особая логика, 2.2 нужен для анализа ожиданий в процентном отношении с учётом DB CPU.
3. Получение данных из таблиц пункта 1 и передача этих данных.
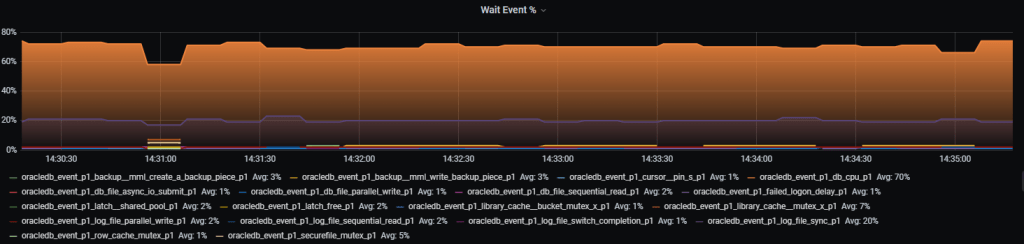
Получение значений ожиданий по каждому классу ожиданий, выраженное в процентах. Сумма всех классов ожиданий не превышает 100%
[[metric]]
context = "db_wait_event"
metricsdesc= { value="System wait event time Diff in %" }
fieldtoappend= "wait_class"
request = '''
with
waitpcts1 as (
select sum(p.time_waited_micro_sum) as timewait1, p.snap_id as snap_id1 from system.kks$system_wait_event p
where p.snap_id=(select max(snap_id) from system.kks$system_wait_event)
group by p.snap_id),
waitpcts2 as (
select sum(p.time_waited_micro_sum) as timewait2,p.snap_id as snap_id2 from system.kks$system_wait_event p
where p.snap_id=(select max(snap_id)-1 from system.kks$system_wait_event)
group by p.snap_id),
wait1 as (
select p.wait_class as wait_class1,p.time_waited_micro_sum as time_waited_micro_sum1,p.snap_id as snap_id1 from system.kks$system_wait_event p
where p.snap_id=(select max(snap_id) from system.kks$system_wait_event)),
wait2 as (
select p.wait_class as wait_class2,p.time_waited_micro_sum as time_waited_micro_sum2,p.snap_id as snap_id12 from system.kks$system_wait_event p
where p.snap_id=(select max(snap_id)-1 from system.kks$system_wait_event))
select wait1.wait_class1 as "wait_class",
round(((wait1.time_waited_micro_sum1-wait2.time_waited_micro_sum2)/decode((waitpcts1.timewait1-waitpcts2.timewait2),0,1,(waitpcts1.timewait1-waitpcts2.timewait2)))*100) as "value"
from wait1,wait2,waitpcts1,waitpcts2
where wait1.wait_class1=wait2.wait_class2
'''
Как это выглядит:
Рис.1
3.2 Получение значения времени по каждому ожиданию(event)(сколько времени потрачено на одно ожидание) выраженное в процентах. Сумма всех ожиданий не превышает 100%.
[[metric]]
context = "event_p1"
metricsdesc= { value="System wait event P1 Diff in % }
fieldtoappend= "wait_event_p1"
request = '''
with
waitpcts1 as (
select sum(p.time_waited_micro_sum) as timewait1, p.snap_id as snap_id1 from system.kks$system_wait_event_p1 p
where p.snap_id=(select max(snap_id) from system.kks$system_wait_event_p1)
group by p.snap_id),
waitpcts2 as (
select sum(p.time_waited_micro_sum) as timewait2,p.snap_id as snap_id2 from system.kks$system_wait_event_p1 p
where p.snap_id=(select max(snap_id)-1 from system.kks$system_wait_event_p1)
group by p.snap_id),
wait1 as (
select p.wait_event as wait_event1,p.time_waited_micro_sum as time_waited_micro_sum1,p.snap_id as snap_id1 from system.kks$system_wait_event_p1 p
where p.snap_id=(select max(snap_id) from system.kks$system_wait_event_p1)),
wait2 as (
select p.wait_event as wait_event2,p.time_waited_micro_sum as time_waited_micro_sum2,p.snap_id as snap_id12 from system.kks$system_wait_event_p1 p
where p.snap_id=(select max(snap_id)-1 from system.kks$system_wait_event_p1))
select replace(replace(replace(wait1.wait_event1,':','_'),'-','_'),'&','_')||'_p1' as "wait_event_p1",
ceil(((wait1.time_waited_micro_sum1-wait2.time_waited_micro_sum2)/decode((waitpcts1.timewait1-waitpcts2.timewait2),0,1,(waitpcts1.timewait1-waitpcts2.timewait2)))*100) as "value"
from wait1,wait2,waitpcts1,waitpcts2
where wait1.wait_event1=wait2.wait_event2
and ceil(((wait1.time_waited_micro_sum1-wait2.time_waited_micro_sum2)/decode((waitpcts1.timewait1-waitpcts2.timewait2),0,1,(waitpcts1.timewait1-waitpcts2.timewait2)))*100)>0
'''
Как это выглядит:
Рис.2
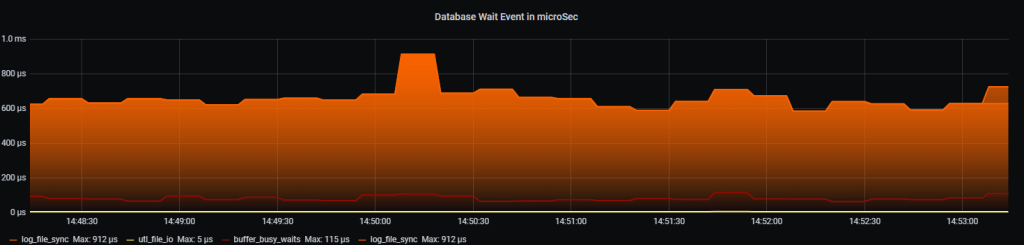
3.3 Сколько времени потрачено на одно событие ожидания(event) в микросекундах.
[[metric]]
context = "event_p2"
metricsdesc= { value="System wait event time P2 Diff in micsec for 4sec." }
fieldtoappend= "wait_event_p2"
request = '''
with
waitpcts1 as (
select p.wait_event as waitevent1,
p.time_waited_micro_sum as timewait1,
p.total_waits_sum as totalwaits1,
p.snap_id as snap_id1
from system.kks$system_wait_event_p2 p
where p.snap_id=(select max(snap_id) from system.kks$system_wait_event_p2)),
waitpcts2 as (
select p.wait_event as waitevent2,
p.time_waited_micro_sum as timewait2,
p.total_waits_sum as totalwaits2,
p.snap_id as snap_id2
from system.kks$system_wait_event_p2 p
where p.snap_id=(select max(snap_id)-1 from system.kks$system_wait_event_p2))
select replace(replace(replace(waitpcts1.waitevent1,':','_'),'-','_'),'&','_')||'_p2' as "wait_event_p2",
ceil(((waitpcts1.timewait1-waitpcts2.timewait2)/decode((waitpcts1.totalwaits1-waitpcts2.totalwaits2),0,1,(waitpcts1.totalwaits1-waitpcts2.totalwaits2)))) as "value"
from waitpcts1,waitpcts2
where waitpcts1.waitevent1=waitpcts2.waitevent2
and ceil(((waitpcts1.timewait1-waitpcts2.timewait2)/decode((waitpcts1.totalwaits1-waitpcts2.totalwaits2),0,1,(waitpcts1.totalwaits1-waitpcts2.totalwaits2))))>0
'''
Как это выглядит:
Рис.3
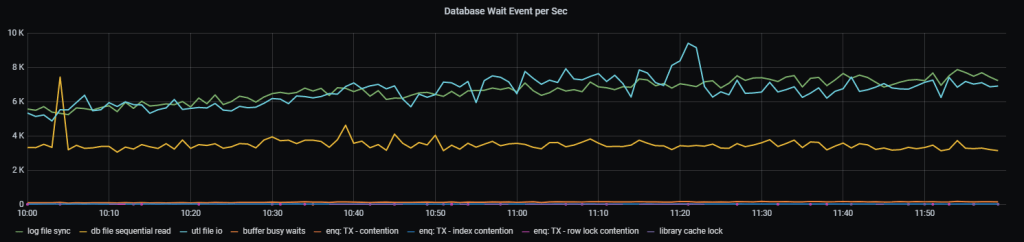
3.3 Количество событий по каждому ожиданию(event) в секунду
[[metric]]
context = "event_p3"
metricsdesc= { value="System wait events P3 Diff for 4sec." }
fieldtoappend= "wait_event_p3"
request = '''
with
waitpcts1 as (
select p.wait_event as waitevent1,
p.total_waits_sum as totalwaits1,
p.snap_id as snap_id1
from system.kks$system_wait_event_p2 p
where p.snap_id=(select max(snap_id) from system.kks$system_wait_event_p2)),
waitpcts2 as (
select p.wait_event as waitevent2,
p.total_waits_sum as totalwaits2,
p.snap_id as snap_id2
from system.kks$system_wait_event_p2 p
where p.snap_id=(select max(snap_id)-1 from system.kks$system_wait_event_p2))
select
replace(replace(replace(waitpcts1.waitevent1,':','_'),'-','_'),'&','_')||'_p2' as "wait_event_p3",
ceil((waitpcts1.totalwaits1-waitpcts2.totalwaits2)/4) as "value"
from waitpcts1,waitpcts2
where waitpcts1.waitevent1=waitpcts2.waitevent2 and ceil(waitpcts1.totalwaits1-waitpcts2.totalwaits2)>0
'''
Как это выглядит:
Рис.4
upd. 25.03.2025, данная статья устарела, но полезна для общего развития, т.к. здесь была положена идея(в 2021г), которая преобразовалась в kPerf for Oracle