При старте сервера приложения Tuxedo получаем ошибку:
ORACLE XA: Version 19.0.0.0.0. RM name = 'Oracle_XA'.
160307.273415.2676717376.0:
ORA-01405: fetched column value is NULL
160307.273415.2676717376.0:
xaorecover: xaofetch rtn -3.
Для решения проблемы нужно зачистить dba_2pc_pending :
select 'rollback force '''||local_tran_id||''' ;' from dba_2pc_pending ;
select 'exec dbms_transaction.purge_lost_db_entry('''||local_tran_id||''' )' , 'commit;' from dba_2pc_pending ;
Manually Resolving In-Doubt Transactions: Different Scenarios (Doc ID 126069.1)
Сделав экcпорт FULL=y CONTENT=metadata_only из бд 19.13, не получается залить дамп в 19.9 по причине ORA-02376: invalid or redundant resource.
На MOS по ошибке ORA-02376 есть нота, DataPump Import Fails With Duplicated Resources In The Create Profile Statement (Doc ID 557383.1), но она не про этот случай.
Корень проблемы в том, что с 19.12 в профиле для пользователей появилась опция PASSWORD_ROLLOVER_TIME в рамках Gradual Database Password Rollover.
При попытке провести импорт дампа, снятого из 19.12 и выше, в бд версии 19.11 и ниже (я проверил только 19.9) создание профиля ломается на ошибке ORA-02376, а далее не создаются пользователи и т.д.
Создать вручную профиль с опцией PASSWORD_ROLLOVER_TIME в 19.9 тоже не получится, эта версия просто не знает про такие опции.
Экспорт с параметром version=19.9, или 19.0 или 12.0 проблему не решает… Переносим профиля отдельно, и заливаем дамп.
upd. 25.03.2025, данная статья устарела, но полезна для общего развития, т.к. здесь была положена идея(в 2021г), которая преобразовалась в kPerf for Oracle
—————————————————————————————————————
Контроль стабильности работы бд требует мониторинга и понимания метрик этого мониторинга. В связи с этим я написал свой небольшой снапер метрик бд и вложил в него ‘своё’ восприятие этих метрик для своих нужд, но возможно общая идея будит интересна ещё кому ни будь.
Мониторинг состоит из нескольких компонентов:
Набор таблиц
Задание по расписанию для заполнения таблиц из пункта 1
Получение данных из таблиц пункта 1 и передача этих данных.
Grafana
Prometheus
OracleDB exporter
Инструкция не содержит пошаговой настройки всех компонентов, а только показывает, как собирается статистика в бд и как обрабатывается.
Набор таблиц.
1.1
CREATE SEQUENCE system.kks$sys_wait_event_sequence
MINVALUE 1
MAXVALUE 999999999999999999999999999
START WITH 1
INCREMENT BY 1
CACHE 20;
create table system.kks$system_wait_event(
wait_class varchar2(256),
TOTAL_WAITS_sum number,
TIME_WAITED_MICRO_sum number,
snap_time date default sysdate,
snap_id number
)
tablespace sysaux;
create index SYSTEM.snap_time_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT (snap_time) tablespace sysaux;
create index SYSTEM.wait_class_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT (wait_class) tablespace sysaux;
create index SYSTEM.snap_id_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT (snap_id) tablespace sysaux;
1.2
CREATE SEQUENCE system.kks$sys_wait_event_sequence_p1
MINVALUE 1
MAXVALUE 999999999999999999999999999
START WITH 1
INCREMENT BY 1
CACHE 20;
create table system.kks$system_wait_event_p1(
wait_event varchar2(256),
TOTAL_WAITS_sum number,
TIME_WAITED_MICRO_sum number,
snap_time date default sysdate,
snap_id number
)
tablespace sysaux;
create index SYSTEM.snap_time_p1_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT_p1 (snap_time) tablespace sysaux;
create index SYSTEM.wait_event_p1_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT_p1 (wait_event) tablespace sysaux;
create index SYSTEM.snap_p1_id_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT_p1 (snap_id) tablespace sysaux;
1.3
CREATE SEQUENCE system.kks$sys_wait_event_sequence_p2
MINVALUE 1
MAXVALUE 999999999999999999999999999
START WITH 1
INCREMENT BY 1
CACHE 20;
create table system.kks$system_wait_event_p2(
wait_event varchar2(256),
TOTAL_WAITS_sum number,
TIME_WAITED_MICRO_sum number,
snap_time date default sysdate,
snap_id number
)
tablespace sysaux;
create index SYSTEM.snap_time_p2_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT_p2 (snap_time) tablespace sysaux;
create index SYSTEM.wait_event_p2_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT_p2 (wait_event) tablespace sysaux;
create index SYSTEM.snap_p2_id_ix on SYSTEM.KKS$SYSTEM_WAIT_EVENT_p2 (snap_id) tablespace sysaux;
2. Задание по расписанию для заполнения таблиц из пункта 1
2.1
Заполняем таблицу из пункта 1.1. Делаем снапшот суммарного количества ожиданий по каждому классу ожиданий(WAIT_CLASS) и суммарного количества времени отведённого для каждого класса ожиданий(WAIT_CLASS), устаревшие данные удалям.
declare
seqno number;
begin
select system.kks$sys_wait_event_sequence.nextval into seqno from dual;
insert into system.kks$system_wait_event(wait_class,total_waits_sum,time_waited_micro_sum,snap_id)
select w.WAIT_CLASS,sum(w.TOTAL_WAITS) totalwaits,sum(w.TIME_WAITED_MICRO) mcsec,seqno from v$system_event w
where w.WAIT_CLASS!='Idle'
group by w.WAIT_CLASS;
insert into system.kks$system_wait_event(wait_class,time_waited_micro_sum,snap_id)
select o.STAT_NAME,o.VALUE,seqno from V$SYS_TIME_MODEL o where o.STAT_NAME='DB CPU';
commit;
delete from system.kks$system_wait_event p1 where p1.snap_time<=sysdate-30/24/60;
commit;
end;
2.2
Заполняем таблицу из пункта 1.2. Делаем снапшот суммарного количества ожиданий по каждому ожиданию(EVENT) и суммарного количества времени отведённого для каждого ожидания(EVENT), устаревшие данные удалям.
declare
seqno number;
begin
select system.kks$sys_wait_event_sequence_p1.nextval into seqno from dual;
insert into system.kks$system_wait_event_p1(wait_event,total_waits_sum,time_waited_micro_sum,snap_id)
select w.EVENT,sum(w.TOTAL_WAITS) totalwaits,sum(w.TIME_WAITED_MICRO) mcsec,seqno from v$system_event w
where w.WAIT_CLASS!='Idle' and w.EVENT!='SQL*Net message to client'
group by w.EVENT;
insert into system.kks$system_wait_event_p1(wait_event,time_waited_micro_sum,snap_id)
select o.STAT_NAME,o.VALUE,seqno from V$SYS_TIME_MODEL o where o.STAT_NAME='DB CPU';
commit;
delete from system.kks$system_wait_event_p1 p1 where p1.snap_time<=sysdate-30/24/60;
commit;
end;
2.3
Заполняем таблицу из пункта 1.3. Делаем снапшот суммарного количества ожиданий по каждому ожиданию(EVENT) и суммарного количества времени отведённого для каждого ожидания(EVENT), устаревшие данные удалям.
declare
seqno number;
begin
select system.kks$sys_wait_event_sequence_p2.nextval into seqno from dual;
insert into system.kks$system_wait_event_p2(wait_event,total_waits_sum,time_waited_micro_sum,snap_id)
select w.EVENT,sum(w.TOTAL_WAITS) totalwaits,sum(w.TIME_WAITED_MICRO) mcsec,seqno from v$system_event w
where w.WAIT_CLASS!='Idle' and w.EVENT!='SQL*Net message to client'
group by w.EVENT;
commit;
delete from system.kks$system_wait_event_p2 p1 where p1.snap_time<=sysdate-30/24/60;
commit;
end;
Я заполняю эти таблицы каждые 5сек. Возможно 2.3 избыточен, т.к. почти такие же данные есть в 2.2. Но тут кроется ‘моя’ особая логика, 2.2 нужен для анализа ожиданий в процентном отношении с учётом DB CPU.
3. Получение данных из таблиц пункта 1 и передача этих данных.
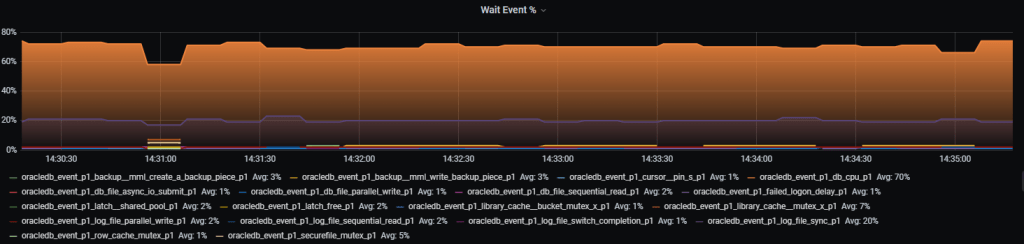
Получение значений ожиданий по каждому классу ожиданий, выраженное в процентах. Сумма всех классов ожиданий не превышает 100%
[[metric]]
context = "db_wait_event"
metricsdesc= { value="System wait event time Diff in %" }
fieldtoappend= "wait_class"
request = '''
with
waitpcts1 as (
select sum(p.time_waited_micro_sum) as timewait1, p.snap_id as snap_id1 from system.kks$system_wait_event p
where p.snap_id=(select max(snap_id) from system.kks$system_wait_event)
group by p.snap_id),
waitpcts2 as (
select sum(p.time_waited_micro_sum) as timewait2,p.snap_id as snap_id2 from system.kks$system_wait_event p
where p.snap_id=(select max(snap_id)-1 from system.kks$system_wait_event)
group by p.snap_id),
wait1 as (
select p.wait_class as wait_class1,p.time_waited_micro_sum as time_waited_micro_sum1,p.snap_id as snap_id1 from system.kks$system_wait_event p
where p.snap_id=(select max(snap_id) from system.kks$system_wait_event)),
wait2 as (
select p.wait_class as wait_class2,p.time_waited_micro_sum as time_waited_micro_sum2,p.snap_id as snap_id12 from system.kks$system_wait_event p
where p.snap_id=(select max(snap_id)-1 from system.kks$system_wait_event))
select wait1.wait_class1 as "wait_class",
round(((wait1.time_waited_micro_sum1-wait2.time_waited_micro_sum2)/decode((waitpcts1.timewait1-waitpcts2.timewait2),0,1,(waitpcts1.timewait1-waitpcts2.timewait2)))*100) as "value"
from wait1,wait2,waitpcts1,waitpcts2
where wait1.wait_class1=wait2.wait_class2
'''
Как это выглядит:
Рис.1
3.2 Получение значения времени по каждому ожиданию(event)(сколько времени потрачено на одно ожидание) выраженное в процентах. Сумма всех ожиданий не превышает 100%.
[[metric]]
context = "event_p1"
metricsdesc= { value="System wait event P1 Diff in % }
fieldtoappend= "wait_event_p1"
request = '''
with
waitpcts1 as (
select sum(p.time_waited_micro_sum) as timewait1, p.snap_id as snap_id1 from system.kks$system_wait_event_p1 p
where p.snap_id=(select max(snap_id) from system.kks$system_wait_event_p1)
group by p.snap_id),
waitpcts2 as (
select sum(p.time_waited_micro_sum) as timewait2,p.snap_id as snap_id2 from system.kks$system_wait_event_p1 p
where p.snap_id=(select max(snap_id)-1 from system.kks$system_wait_event_p1)
group by p.snap_id),
wait1 as (
select p.wait_event as wait_event1,p.time_waited_micro_sum as time_waited_micro_sum1,p.snap_id as snap_id1 from system.kks$system_wait_event_p1 p
where p.snap_id=(select max(snap_id) from system.kks$system_wait_event_p1)),
wait2 as (
select p.wait_event as wait_event2,p.time_waited_micro_sum as time_waited_micro_sum2,p.snap_id as snap_id12 from system.kks$system_wait_event_p1 p
where p.snap_id=(select max(snap_id)-1 from system.kks$system_wait_event_p1))
select replace(replace(replace(wait1.wait_event1,':','_'),'-','_'),'&','_')||'_p1' as "wait_event_p1",
ceil(((wait1.time_waited_micro_sum1-wait2.time_waited_micro_sum2)/decode((waitpcts1.timewait1-waitpcts2.timewait2),0,1,(waitpcts1.timewait1-waitpcts2.timewait2)))*100) as "value"
from wait1,wait2,waitpcts1,waitpcts2
where wait1.wait_event1=wait2.wait_event2
and ceil(((wait1.time_waited_micro_sum1-wait2.time_waited_micro_sum2)/decode((waitpcts1.timewait1-waitpcts2.timewait2),0,1,(waitpcts1.timewait1-waitpcts2.timewait2)))*100)>0
'''
Как это выглядит:
Рис.2
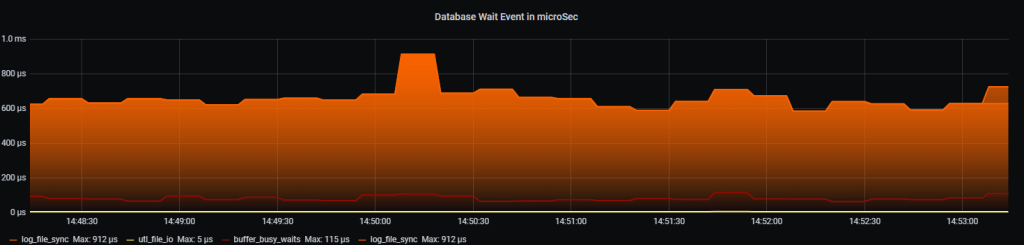
3.3 Сколько времени потрачено на одно событие ожидания(event) в микросекундах.
[[metric]]
context = "event_p2"
metricsdesc= { value="System wait event time P2 Diff in micsec for 4sec." }
fieldtoappend= "wait_event_p2"
request = '''
with
waitpcts1 as (
select p.wait_event as waitevent1,
p.time_waited_micro_sum as timewait1,
p.total_waits_sum as totalwaits1,
p.snap_id as snap_id1
from system.kks$system_wait_event_p2 p
where p.snap_id=(select max(snap_id) from system.kks$system_wait_event_p2)),
waitpcts2 as (
select p.wait_event as waitevent2,
p.time_waited_micro_sum as timewait2,
p.total_waits_sum as totalwaits2,
p.snap_id as snap_id2
from system.kks$system_wait_event_p2 p
where p.snap_id=(select max(snap_id)-1 from system.kks$system_wait_event_p2))
select replace(replace(replace(waitpcts1.waitevent1,':','_'),'-','_'),'&','_')||'_p2' as "wait_event_p2",
ceil(((waitpcts1.timewait1-waitpcts2.timewait2)/decode((waitpcts1.totalwaits1-waitpcts2.totalwaits2),0,1,(waitpcts1.totalwaits1-waitpcts2.totalwaits2)))) as "value"
from waitpcts1,waitpcts2
where waitpcts1.waitevent1=waitpcts2.waitevent2
and ceil(((waitpcts1.timewait1-waitpcts2.timewait2)/decode((waitpcts1.totalwaits1-waitpcts2.totalwaits2),0,1,(waitpcts1.totalwaits1-waitpcts2.totalwaits2))))>0
'''
Как это выглядит:
Рис.3
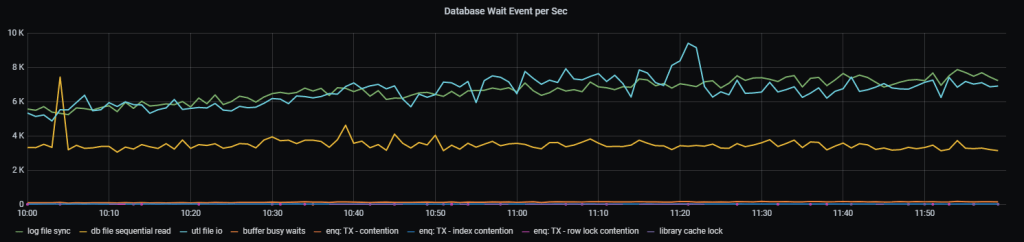
3.3 Количество событий по каждому ожиданию(event) в секунду
[[metric]]
context = "event_p3"
metricsdesc= { value="System wait events P3 Diff for 4sec." }
fieldtoappend= "wait_event_p3"
request = '''
with
waitpcts1 as (
select p.wait_event as waitevent1,
p.total_waits_sum as totalwaits1,
p.snap_id as snap_id1
from system.kks$system_wait_event_p2 p
where p.snap_id=(select max(snap_id) from system.kks$system_wait_event_p2)),
waitpcts2 as (
select p.wait_event as waitevent2,
p.total_waits_sum as totalwaits2,
p.snap_id as snap_id2
from system.kks$system_wait_event_p2 p
where p.snap_id=(select max(snap_id)-1 from system.kks$system_wait_event_p2))
select
replace(replace(replace(waitpcts1.waitevent1,':','_'),'-','_'),'&','_')||'_p2' as "wait_event_p3",
ceil((waitpcts1.totalwaits1-waitpcts2.totalwaits2)/4) as "value"
from waitpcts1,waitpcts2
where waitpcts1.waitevent1=waitpcts2.waitevent2 and ceil(waitpcts1.totalwaits1-waitpcts2.totalwaits2)>0
'''
Как это выглядит:
Рис.4
upd. 25.03.2025, данная статья устарела, но полезна для общего развития, т.к. здесь была положена идея(в 2021г), которая преобразовалась в kPerf for Oracle
insert into TUSER.tab3(PANID,DESCSTR) values('1444555566667779','testPAN');
insert into TUSER.tab3(PANID,DESCSTR) values('2444555566667779','testPAN');
insert into TUSER.tab3(PANID,DESCSTR) values('3444555566667779','testPAN');
commit;
Now, in receiver, target TUSER.tab4 use map rule with SQLEXEC and QUERY clause, and target TUSER.tab3 use map rule with only Goldengate function.
Result on receiver:
SQL> select panid, 'tab4' as tabname from TUSER.tab4
2 union all
3 select panid, 'tab3' as tabname from TUSER.tab3
4 ;
PANID TABNAME
-------------------- -------
1444557779 tab4
2444557779 tab4
3444557779 tab4
144455******7779 tab3
244455******7779 tab3
344455******7779 tab3
6 rows selected
How data looks like on Kafka side(can also be receiver) after masking if using rule:
При выполнений пакетных заданий и не только было замечено интересное — фрагментация таблиц, где казалось бы её не должно быть(или должно?).
Для проверки влияния был составлен тест из 3 циклов:
1 цикл — главный.
2 цикл находится внутри цикла 1, выполняет вставку.
3 цикл находится внутри цикла 1, выполняет удаление.
Количество проходов циклов 2 и 3 одинаково и задаётся при старте, циклы выполняются друг за другом, commit выполняется после каждой удалённой или вставленной строки.
Тест проводится с участим трёх таблиц(KKS$FRAG_512B, KKS$FRAG_1024B, KKS$FRAG_2048B), в которых длина вставляемой строки заранее известна, это 512байт, 1024байт и 2048байта. Размер сегмента берётся из dba_segments.
Для таблиц KKS$FRAG_512B, KKS$FRAG_1024B, KKS$FRAG_2048B было выполнено:
Количество циклов
Количество операций вставок и удалений в каждом цикле
303
2003
606
1006
606
706
606
506
606
106
Таб.1
Результат для KKS$FRAG_512B:
12.1.0.2.190716 BP, занято байт в таблице KKS$FRAG_512B
33554432
12.1.0.2.190716 BP, занято блоков в таблице KKS$FRAG_512B
4096
19.7.0.0.200414 RU, занято байт в таблице KKS$FRAG_512B
7340032
19.7.0.0.200414 RU, занято блоков в таблице KKS$FRAG_512B
896
Таб.2 KKS$FRAG_512B
Различие в размере сегмента составляет 4,5 раза.
2. Результат для KKS$FRAG_1024B:
12.1.0.2.190716 BP, занято байт в таблице KKS$FRAG_1024B
33554432
12.1.0.2.190716 BP, занято блоков в таблице KKS$FRAG_1024B
4096
19.7.0.0.200414 RU, занято байт в таблице KKS$FRAG_1024B
9437184
19.7.0.0.200414 RU, занято блоков в таблице KKS$FRAG_1024B
1152
Таб.3 KKS$FRAG_1024B
Отличие скромнее, но оно по прежнему существенно — в 3,5 раза.
3. Результат для KKS$FRAG_2048B:
12.1.0.2.190716 BP, занято байт в таблице KKS$FRAG_2048B
19922944
12.1.0.2.190716 BP, занято блоков в таблице KKS$FRAG_2048B
2432
19.7.0.0.200414 RU, занято байт в таблице KKS$FRAG_2048B
16777216
19.7.0.0.200414 RU, занято блоков в таблице KKS$FRAG_2048B
2048
Таб.4 KKS$FRAG_2048B
Разница не велика, но она есть: 1,18 раза
4. Другой профиль нагрузки для KKS$FRAG_512B.
Количество циклов
Количество операций вставок и удалений в каждом цикле
2002
1002
Таб.5 KKS$FRAG_512B
12.1.0.2.190716 BP, занято байт в таблице KKS$FRAG_512B
46137344
12.1.0.2.190716 BP, занято блоков в таблице KKS$FRAG_512B
5632
19.7.0.0.200414 RU, занято байт в таблице KKS$FRAG_512B
720896
19.7.0.0.200414 RU, занято блоков в таблице KKS$FRAG_512B
88
Таб.6 KKS$FRAG_2048B
Разница: в 64 раза
5. Другой профиль нагрузки для KKS$FRAG_1024B.
Количество циклов
Количество операций вставок и удалений в каждом цикле
2002
1002
Таб.7 KKS$FRAG_1024B
Результат:
12.1.0.2.190716 BP, занято байт в таблице KKS$FRAG_1024B
262144
12.1.0.2.190716 BP, занято блоков в таблице KKS$FRAG_1024B
32
19.7.0.0.200414 RU, занято байт в таблице KKS$FRAG_1024B
196608
19.7.0.0.200414 RU, занято блоков в таблице KKS$FRAG_1024B
24
Таб.6 KKS$FRAG_1024B
Разница: в 1.3 раза
Исходя из результатов тестов можно сделать вывод: при переходе на версию 19с, рост бд возможно замедлиться при одинаковой нагрузке. Самое время понять, что приводит к такому различию размеров таблиц.
А сессии приложения находятся в ожидании XDB SGA initialization.
Если поискать на MOS по этим входным данным, то все они сводятся к выставлению переменной окружения LD_LIBRARY_PATH / LIBPATH / SHLIB_PATH(в зависимости от платформы), либо, идёт указание на то, что компонент XDB повреждён, в следствии апгрейда либо ещё чего, и нужно его переставить/исправить.
Но в данном случае все выше перечисленные решения на MOS не рабочие.
Ларчик открывается легко, просто нужно подождать, 5-10мин после входа первой сессии от приложения, после чего в алертлоге фиксируется:
XDB installed.
XDB initialized.
после чего ошибка не повторяется.
Данное долгое инициализирование XDB замечено только на Solaris.
Я буду отключать диски, и наблюдать, как поведёт себя ASM и база данных, а также данная статья призвана пролить свет на количественные характеристики показателей свободного, занятого, и прочего места в ASM, при проведение эксперимента и ответить на вопрос ‘а что если..?’.
Версия ASM 12.1.0.2.190716
Конфигурация: Дисковая группа из шести дисков и двух Failgroup, по 3 диска в каждой FG, с избыточностью Normal.
SQL> create diskgroup kksdg1 normal redundancy failgroup fg1 disk 'ORCL:DISK1','ORCL:DISK2','ORCL: DISK7' failgroup fg2 disk 'ORCL:DISK3','ORCL:DISK4','ORCL:DISK4N';
Diskgroup created.
Req_mir_free_MB — зарезервировал по одному диску на каждую failgroup, и того зарезервировано 2 диска.
Все диски в дисковой группе заполнились равномерно(внимание на колонку Free_MB).
1.2 Проверим устойчивость дисковой группы к выходу из строя дисков:
Я выставил ‘DISK_REPAIR_TIME’=’1m’ для дисковой группы.
1.2.1 Отключаем первый диск(DISK1):
[root@kks grid12]# oracleasm querydisk -d DISK1
Disk "DISK1" is a valid ASM disk on device [8,81]
[root@kks grid12]# ls -l /dev/* | grep 8, | grep 81
brw-rw---- 1 root disk 8, 81 Aug 5 15:56 /dev/sdf1
[root@kks grid12]# echo 1 > /sys/block/sdf/device/delete
ASM Alert log:
Wed Aug 05 16:24:36 2020
Errors in file /grid/app/diag/asm/+asm/+ASM/trace/+ASM_gmon_2966.trc:
ORA-15186: ASMLIB error function = [kfk_asm_ioerror], error = [0], mesg = [I/O Error]
Wed Aug 05 16:24:36 2020
NOTE: PST update grp = 2 completed successfully
Wed Aug 05 16:25:22 2020
WARNING: Started Drop Disk Timeout for Disk 0 (DISK1) in group 2 with a value 60
WARNING: Disk 0 (DISK1) in group 2 will be dropped in: (60) secs on ASM inst 1
DB Alert log:
Wed Aug 05 16:24:36 2020
NOTE: updating disk modes to 0x5 from 0x7 for disk 0 (DISK1) in group 2 (KKSDG1): lflags 0x0
NOTE: disk 0 (DISK1) in group 2 (KKSDG1) is offline for reads
NOTE: updating disk modes to 0x1 from 0x5 for disk 0 (DISK1) in group 2 (KKSDG1): lflags 0x0
NOTE: disk 0 (DISK1) in group 2 (KKSDG1) is offline for writes
ASM Alert log:
Wed Aug 05 16:28:29 2020
SUCCESS: alter diskgroup KKSDG1 drop disk DISK1 force /* ASM SERVER */
По прошествии нескольких минут диск был удалён, ребаланс прошел успешно.
1.2.2 Отключаем второй диск(DISK2):
[root@kks grid12]# oracleasm querydisk -d DISK2
Disk "DISK2" is a valid ASM disk on device [8,129]
[root@kks grid12]# ls -l /dev/* | grep 8, | grep 129
brw-rw---- 1 root disk 8, 129 Aug 5 15:56 /dev/sdi1
[root@kks grid12]# echo 1 > /sys/block/sdi/device/delete
ASM Alert log:
Wed Aug 05 16:34:44 2020
WARNING: Started Drop Disk Timeout for Disk 1 (DISK2) in group 2 with a value 60
WARNING: Disk 1 (DISK2) in group 2 will be dropped in: (60) secs on ASM inst 1
Errors in file /grid/app/diag/asm/+asm/+ASM/trace/+ASM_gmon_2966.trc:
ORA-15186: ASMLIB error function = [kfk_asm_ioerror], error = [0], mesg = [I/O Error]
…………………………………..
Wed Aug 05 16:37:51 2020
SUCCESS: alter diskgroup KKSDG1 drop disk DISK2 force /* ASM SERVER */
DB Alert log:
Wed Aug 05 16:32:47 2020
NOTE: updating disk modes to 0x5 from 0x7 for disk 1 (DISK2) in group 2 (KKSDG1): lflags 0x0
NOTE: disk 1 (DISK2) in group 2 (KKSDG1) is offline for reads
NOTE: updating disk modes to 0x1 from 0x5 for disk 1 (DISK2) in group 2 (KKSDG1): lflags 0x0
NOTE: disk 1 (DISK2) in group 2 (KKSDG1) is offline for writes
На данном этапе получилось, что ребаланc завешается ошибкой ORA-15041, недостаточно места в дисковой группе и в FG1 в частности, чтобы провести ребаланс.
Данный диск _DROPPED_0001_KKSDG1 не удаляется, а переименовался, бд по-прежнему доступна и таблицы в табличном пространстве kkstbs1 тоже живы, также Usable_file_MB в минусе.
В Alert log BD:
Wed Aug 05 16:37:51 2020
SUCCESS: disk DISK2 (1.3916017828) renamed to _DROPPED_0001_KKSDG1 in diskgroup KKSDG
1.2.3 Отключаем третий диск(DISK7):
[root@kks grid12]# oracleasm querydisk -d DISK7
Disk "DISK2" is a valid ASM disk on device [8, 161]
[root@kks ~]# ls -l /dev/* | grep 8, | grep 161
brw-rw---- 1 root disk 8, 161 Aug 6 13:17 /dev/sdk1
[root@kks ~]# echo 1 > /sys/block/sdk/device/delete
Остановим бд и перемонтируем дисковую группу, проверим, не потеряю ли я группу на данном этапе:
SQL> alter diskgroup kksdg1 dismount;
Diskgroup altered.
SQL> alter diskgroup kksdg1 mount;
Diskgroup altered.
Может показаться, что если невозможно провести ребаланс, по причине ошибки ORA-15041, ASM не удалят диски, а переименовывает их.
Но это только показалось, в ходе эксперимента было десятки кейсов удаления дисков, и поведение может отличаться. Например, если удалить, созданное на этой дисковой группе табличное пространство kkstbs1, то произойдёт это:
SUCCESS: grp 2 disk _DROPPED_0000_KKSDG1 going offline
SUCCESS: grp 2 disk _DROPPED_0001_KKSDG1 going offline
NOTE: Disk _DROPPED_0000_KKSDG1 in mode 0x0 marked for de-assignment
NOTE: Disk _DROPPED_0001_KKSDG1 in mode 0x0 marked for de-assignment
диски удалятся, но последующие несколько экспериментов показали, что это не всегда так.
Какой в этом смысл? Зачем держать эти диски, которых фактически нет.
Также, если удалять дисковую группу через drop diskgroup force including contents, то повторное использование дисков не требует зачистки их заголовков через dd, если использовать просто drop diskgroup, то нужно чистить заголовок диска, чтобы его повторно использовать(это особенность asm 12), force можно применить если группа не замонтирована.
И на сладкое, двойное удаление дисковой группы(тест на то, что заголовки дисков живы после удаления группы):
SQL> drop diskgroup kksdg1 force including contents;
drop diskgroup kksdg1 force including contents
*
ERROR at line 1:
ORA-15039: diskgroup not dropped
ORA-15230: diskgroup 'KKSDG1' does not require the FORCE option
SQL> drop diskgroup kksdg1;
Diskgroup dropped.
SQL> drop diskgroup kksdg1 force including contents;
drop diskgroup kksdg1 force including contents
*
ERROR at line 1:
ORA-15039: diskgroup not dropped
ORA-15063: ASM discovered an insufficient number of disks for diskgroup
"KKSDG1"
SQL> alter diskgroup kksdg1 mount;
alter diskgroup kksdg1 mount
*
ERROR at line 1:
ORA-15032: not all alterations performed
ORA-15017: diskgroup "KKSDG1" cannot be mounted
ORA-15040: diskgroup is incomplete
SQL> drop diskgroup kksdg1 force including contents; <----- Здесь я вернул отключенные диски(просканировав шину SCSI ) и смогу удалить дисковую группу ещё раз 0_о
Diskgroup dropped.
SQL>
Вероятно будет часть 3 и версия asm 19, с применением утилит ASM tools used by Support : KFOD, KFED, AMDU (Doc ID 1485597.1), т.к. как всегда(у меня), вопросов больше, чем ответов.
В первоисточнике вы можете подробнее ознакомится с механизмами и параметрами, которые будут упомянутs здесь, я же только опишу конечный результат, который получился у меня.
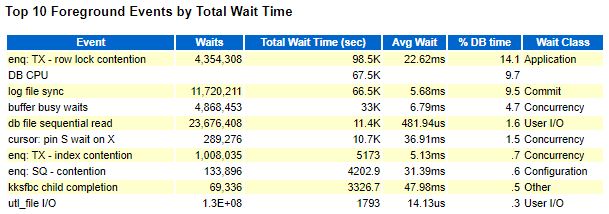
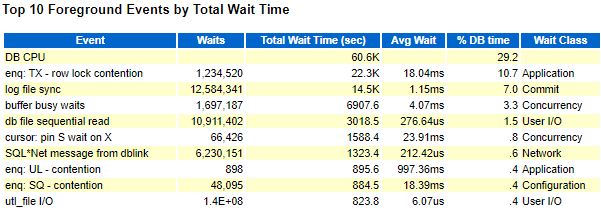
Описание проблемы: после того как бд переехала на сервер с 4мя сокетами, по достижению определённой нагрузки, резко вырастали ожидания log file sync и buffer busy wait.
Промежутки времени для AWR и Lab128 взяты немного разные, поэтому есть разница в цифрах, но общей картины это не меняет, всё очень плохо.
1. Первым делом решено было бороться с log file sync(LFS).
Из ссылки 1 я узнаю про параметр _log_parallelism_max.
Критерии, по которым можно попробовать оценить, есть ли смыл в изменении его значения по умолчанию:
1. Ожидание log file sync гораздо выше(более чем в 2 раза) log file parallel write
Например, log file sync= 1мс, а log file parallel write=2мс и выше.
2. Оценить значении log file parallel write P3(Number of I/O requests) из v$active_session_history/dba_active_session_history в нагруженный и не нагруженный период. P3 должен изменяться, от 1 до _log_parallelism_max т.е. быть 2,3,4,5…
3. При повышении значения log file parallel write P3(Number of I/O requests), log file sync должен расти, но возможно не обязан.
4. Количество потоков CPU больше, либо равно 64.
5. Log File Parallel Writes Take Longer with a Higher CPU Count (Doc ID 1980199.1)
Я применил значение _log_parallelism_max=2
Результат:
AWR:
log file sync снизился с 5.68мс до 1.15мс(по AWR), казалось бы победа, но нет, присутствует ожидание buffer busy wait, которое оказывает сильное влияние на работу приложения, да и само значение log file sync всё ещё выше, чем на старом сервере, даже после улучшения.
2. Здесь переходим ко второй части.
Ожидания buffer busy wait с работой приложения никак не связано, профиль нагрузки практически не менялся. Kоличественные характеристики полезной работы бд: dml выполненных в секунду, количество коммитов в секунду, LIO в секунду в целом выросли на 5%-10% и после переезда на 4 сокета, buffer busy wait раскрылся во всей красе, опять таки только по достижению определённой нагрузки(превышение на 5%-10%), если её не превышать, то всё хорошо.
Всё хорошо — это означает, что ожидания buffer busy wait стремятся к нулю, а log file sync значительно меньше 1мс (0.3-0.6мс) для работы под нужной нагрузкой.
Вышеописанное должно привести на мысль, что что-то не так с железом, либо проблема на уровне OS. Здесь на помощь приходит вторая ссылка, из которой становится понятно, что вероятно дело в kernel.numa_balancing. И действительно, если поискать на MOS используя kernel.numa_balancing, то получим:
Requirements for Installing Oracle Database 19c on OL7 or RHEL7 64-bit (x86-64) (Doc ID 2551169.1)
(EX39) NUMA-enabled database servers experience continuously high load or reduced performance after updating to Exadata 12.2.1.1.0 or higher. (Doc ID 2319324.1)
А также из общедоступных источников: Optimal Configuration of Memory System
Откуда следует вывод, что без kernel.numa_balancing=0 никуда. И действительно, после применения данного параметра, производительность бд значительно выросла:
В итоге, конфигурация имеет значение _log_parallelism_max=2 на уровне бд и kernel.numa_balancing=0 на уровне ОС.
Также эксперимент был проведён на Solaris Sparc:
Solaris Sparc : 11.4+patch
Oracle 12.1.0.2 + BP
ASM 19.7
И _log_parallelism_max=2 VS_log_parallelism_max=1:
Нагрузка тут уже в 3 раза выше, чем на Linux, а снижение LFS c 0.77 мс до 0.60 мс дало прирост быстродействия на стороне приложения до 30%.
Также _log_parallelism_max=1 снизил потребление ЦПУ на 7%.
Выводов нет, делайте их сами, а использование скрытых параметров должно быть обоснованным и обдуманным решением.