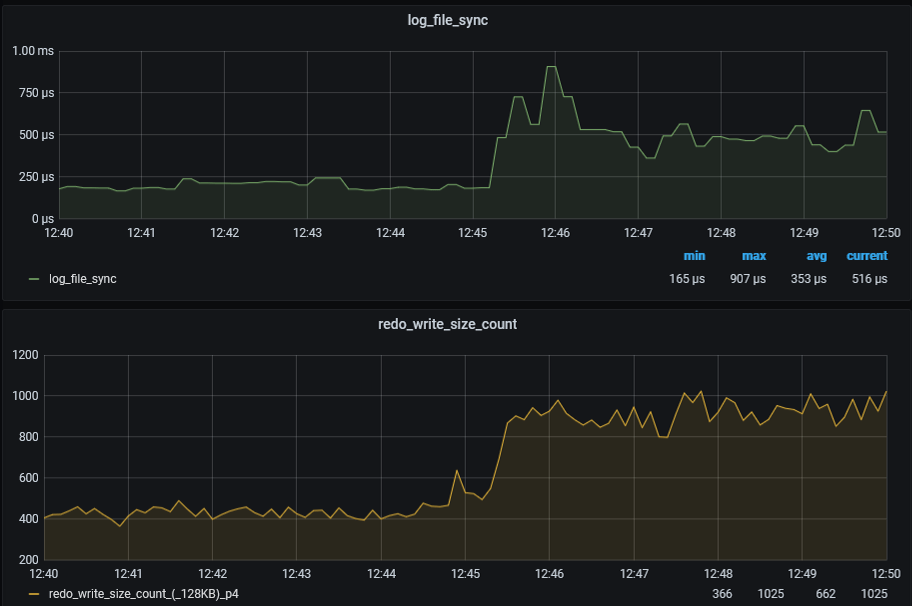
Проблема: Имеется мёртвая(Dead) транзакция которая откатывается со скоростью 1-2 блока в секунду, которая блокирует выполнение update/delete/insert с ожиданием transaction(event#=1074, name=transaction). Версия Oracle: 19.21.
Т.к. откат транзакции может занять значительное время, самое время как то помочь этому процессу. Для этого, нужно дропнуть обьект, с которым связана транзакция из-за которого откат идёт очень медленно. Как определить объект который нужно дропунуть? Вот тут всё может быть не однозначно, т.к. в транзакции может быть замешано N таблиц. В моём случае я включил трассировку 10046 для процесса SMON, в которой были ожидания вида ‘enq: CR — block range reuse ckpt’ obj#=МойПроблемныйОбъект, далее я сдампил ещё заголовок undo сегмента(alter system dump undo header «_ИмяСегмента») и ундо блоки связанные с транзакцией (alter system dump undo block «_ИмяСегмента» XID номер_USN номер_SLT номер_SEQ).
Откуда, что берём:
USN, SLT,SEQ- из select * from v$fast_start_transactions
_ИмяСегмента- из Select * from v$rollname where usn = USNВ дампе блоков связанных с транзакцией кучи вот такого:
KTSL - LOB Persistent Undo Block (PUB) undo record.Есть подозрения, что KTSL это -Kernel Transaction Segment LOB, но это не точно. В дампе заголовка ундо и в дампе блоков связанных с транзакцией, должна быть связь в виде: в заголовке ундо сегмента в разделе TRN TBL, в колонке cmt есть значение 0, а в колонке dba на этом же уровне, имеются координаты блока, сдампив который, мы попадём в UBA, который связан с alter system dump undo block «_ИмяСегмента» XID номер_USN номер_SLT номер_SEQ.
Нужно взять книжку Oracle Core от Jonathan Lewis, и ещё раз перечитать....Проанализировав кучу текста, выбираем нужный обьект и дропаем))):
alter system set "_smu_debug_mode"=1024;
oradebug setospid <ospid of SMON process>
oradebug event 10513 trace name context forever, level 2
drop table owner.table purge;
purge recyclebin;
oradebug event 10513 trace name context off
alter system set "_smu_debug_mode"=0;Так же, я использовал fast_start_parallel_rolback=false;(переключение этого параметра может остановить процесс отката, тут либо инстанс перезапускать, либо пытаться оживить SMON).
Откат транзакции ускорится в сотни раз. Как завершится, создаём таблицу по новой.
Полезные ноты:
Database Hangs Because SMON Is Taking 100% CPU Doing Transaction Recovery (Doc ID 414242.1)
IF: Transaction Recovery or Rollback of Dead Transactions (Doc ID 1951738.1)Отдельно хочу отметить:
Bug 11790175 — SMON spins in rollback of LOB due to double allocated block like bug 11814891 (Doc ID 11790175.8)
Это древний баг, описание которого в моём случае совпадает только по двум критериям:
- Медленный откат
- Проблемный объект: LOB
UNDO и REDO, тяжелая тема… возможно есть метод и попроще.