In case you are using an Oracle Cloud Free Tier instance (VM.Standard.E2.1.Micro), I would recommend checking how much RAM is available in your OS. In my case, it has only 512 MB of RAM:
The problem was in the parameter crashkernel=1G-64G:448M,64G-:512M, which was located in GRUB. I have no idea why crashkernel needs so much memory… on an instance where only 1 GB of RAM is available. But the funny thing is, sometimes when you reboot your instance, it gets slightly more or less RAM than 1 GB — about +-20–30 KB or less.. And in that case, when RAM is less than 1 GB, the crashkernel does not work and the OS just uses 1 GB.
To remove crashkernel from the boot parameters, run this command and then reboot the instance:
Usable_file_MB — available (protected) space considering redundancy.
Req_mir_free_MB — the amount of space required to restore full redundancy after the most severe failure that the disk group can tolerate.
1.1 Adding a disk to the group:
SQL> ALTER DISKGROUP testkks1 ADD DISK 'ORCL:DISK3';
Diskgroup altered.
Checking the result:
What do we see here:
Total_MB — increased by the size of one disk.
Free_MB — increased by the size of one disk.
Req_mir_free_MB — increased by the size of one disk.
Usable_file_MB — remained unchanged at 5042.
1.2 Removing a disk:
We’re back to where we started.
1.3 Adding two disks to the disk group:
SQL> ALTER DISKGROUP testkks1 ADD DISK 'ORCL:DISK3','ORCL:DISK4' REBALANCE POWER 9 WAIT;
Diskgroup altered.
Checking the result:
What do we see here:
Total_MB — increased by the size of two disks.
Free_MB — increased by the size of two disks.
Req_mir_free_MB — equals the size of one disk.
Usable_file_MB — changed, increasing by half the size of one disk.
Adding one more disk:
SQL> ALTER DISKGROUP testkks1 ADD DISK 'ORCL:DISK5' REBALANCE POWER 9 WAIT;
Diskgroup altered.
Total_MB — increased by the size of one disk.
Free_MB — increased by the size of one disk.
Req_mir_free_MB — equals the size of one disk (unchanged).
Usable_file_MB — changed, increasing by half the size of one disk.
Now, let’s conclude that:
Total_MB — represents the total amount of raw space.
Free_MB — represents the total amount of free raw space.
Req_mir_free_MB — equals the size of one disk if Normal redundancy is specified, the number of disks is three or more, and no Failgroup is explicitly assigned for each disk during disk group creation.
From this, it follows that with Normal redundancy and three or more disks, Usable_file_MB will be equal to:
Usable_file_MB=(Free_MB — Req_mir_free_MB)/2
For 5 disks, with Normal redundancy:
Usable_file_MB=(25438-5119)/2= 10 159
For 4 disks, with Normal redundancy:
Usable_file_MB=(20321-5119)/2=7 601
For 3 disks, with Normal redundancy:
Usable_file_MB=(15204-5119)/2= 5 042
For 2 disks, with Normal redundancy:
Usable_file_MB=(10136-0)/2= 5 068
The edge case for 3 disks shows that, starting from this number of disks, ASM begins reserving 1 disk to restore full redundancy after the most severe failure that can be tolerated by the disk group.
Configuration 2: A disk group with two disks, Normal redundancy, and its filling.
1.1 Initial state:
Filling the disk group:
SQL> create tablespace kkstbs1 datafile '+TESTKKS1' size 5050M autoextend on next 10m;
Tablespace created.
Result:
Expanding the data file by another 10MB:
SQL> alter database datafile '+TESTKKS1/kksdb/DATAFILE/KKSTBS1.256.1046190953' resize 5060M;
Database altered.
Result:
Expanding by another 10MB:
SQL> alter database datafile '+TESTKKS1/kksdb/DATAFILE/KKSTBS1.256.1046190953' resize 5070M;
alter database datafile '+TESTKKS1/kksdb/DATAFILE/KKSTBS1.256.1046190953' resize 5070M
*
ERROR at line 1:
ORA-01237: cannot extend datafile 5
ORA-01110: data file 5: '+TESTKKS1/KKSDB/DATAFILE/kkstbs1.256.1046190953'
ORA-17505: ksfdrsz:1 Failed to resize file to size 648960 blocks
ORA-15041: diskgroup "TESTKKS1" space exhausted
Not so fast.
1.2 Adding a disk:
SQL> ALTER DISKGROUP testkks1 ADD DISK 'ORCL:DISK3' REBALANCE POWER 9 WAIT;
Diskgroup altered.
At this stage, we conclude that Usable_file_MB went negative due to one disk being reserved for restoring full redundancy after the most severe failure that can be tolerated by the disk group. Otherwise, we would encounter ORA-15041, which indicates that the disk group has run out of space.
Additionally, we note that data started being written to this disk long before Usable_file_MB became negative.
Obviously, further filling of the disk group is pointless since, at this stage, the maximum negative value we can reach is Usable_file_MB = -5119.
REQUIRED_MIRROR_FREE_MB indicates the amount of space that must be available in a disk group to restore full redundancy after the worst failure that can be tolerated by the disk group without adding additional storage. This requirement ensures that there are sufficient failure groups to restore redundancy. Also, this worst failure refers to a permanent failure where the disks must be dropped, not the case where the disks go offline and then back online.
According to this description, in the current situation (Usable_file_MB is negative, and the so-called «reserved» disk already contains more data than it should), if we suddenly lose one disk, something very interesting will happen.
Checking the scenario: Losing a disk.
SQL> alter diskgroup testkks1 set attribute 'DISK_REPAIR_TIME'='10m';
Diskgroup altered.
— Here, I changed the device type from NVMe to SCSI (which changed the Failgroup names) because I couldn’t find a proper way to disconnect an NVMe disk on a virtual machine. 😆 —
NOTE: updating disk modes to 0x5 from 0x7 for disk 3 (DISK1) in group 2 (TESTKKS1): lflags 0x0
NOTE: disk 3 (DISK1) in group 2 (TESTKKS1) is offline for reads
NOTE: updating disk modes to 0x1 from 0x5 for disk 3 (DISK1) in group 2 (TESTKKS1): lflags 0x0
NOTE: disk 3 (DISK1) in group 2 (TESTKKS1) is offline for writes
Rebalance has not started yet; less than 10 minutes have passed since the disk was lost:
Let’s try expanding the data file by another 1024MB:
SQL> alter database datafile '+TESTKKS1/kksdb/DATAFILE/KKSTBS1.256.1046190953' resize 7098M;
Database altered.
Here are two peculiarities:
Strangeness #1: Even though the lost disk «disk 3 (DISK1) in group 2 (TESTKKS1) is offline for writes,» its Free_MB decreased from 1012MB to 332MB.
Strangeness #2: The maximum possible Usable_file_MB in this configuration is 5042MB, yet the data file size at the moment of disk removal was 6074MB.
After the DISK_REPAIR_TIME = '10m' elapsed, the disk was successfully removed:
SUCCESS: alter diskgroup TESTKKS1 drop disk DISK1 force /* ASM SERVER */
However, the disk remained, renamed as _DROPPED_0003_TESTKKS1.
Attempts to rebalance or add a 10MB file were unsuccessful.
ORA-15041: diskgroup "TESTKKS1" space exhausted
WARNING: Rebalance encountered ORA-15041; continuing
SQL> alter tablespace kkstbs1 add datafile '+TESTKKS1' size 10m;
alter tablespace kkstbs1 add datafile '+TESTKKS1' size 10m
*
ERROR at line 1:
ORA-01119: error in creating database file '+TESTKKS1'
ORA-17502: ksfdcre:4 Failed to create file +TESTKKS1
ORA-15041: diskgroup "TESTKKS1" space exhausted
Summary of the Current Situation:
A disk group with Normal redundancy consisting of three disks has effectively turned into a two-disk group.
With two or three disks, the Usable_file_MB of the disk group is 5,042MB.
When a disk is lost and Usable_file_MB goes negative, redundancy is lost for the data that caused the negative value. Currently, the tablespace size is 7,098MB, exceeding the usable limit.
If one more disk fails, it will lead to either tablespace loss or complete disk group failure.
If you want to install Oracle 23ai Free to a specific ORACLE_HOME rather than using /opt on Linux, you can do it by following the next instructions.
First, extract the cpio archive from the RPM package. I used 7-Zip for Windows.)))
Next, extract the cpio archive: cpio -idv < ./oracle-database-free-23ai-1.0-1.x86_64.cpio
After unpacking the cpio archive, you will have ./etc, ./opt, and ./usr.
In the folder ./opt/oracle/product/23ai/dbhomeFree, we can find what we are looking for—the Oracle 23ai Free distribution.
Copy or move the dbhomeFree folder to the desired ORACLE_HOME.
Installation: I recommend choosing Software Only, and then deploying the database later using DBCA.
During installation, you can select any edition, but it won’t make any difference.
There will also be around 18 errors related to library linking- skip them. For example:
Error in invoking target 'install' of makefile '/orcle/app/dbhome23ai/srvm/lib/ins_srvm.mk'.
Error in invoking target 'utilities' of makefile '/orcle/app/dbhome23ai/rdbms/lib/ins_rdbms.mk'.
Error in invoking target 'iokdstry iokinit' of makefile '/orcle/app/dbhome23ai/network/lib/ins_nau.mk'.
Error in invoking target 'install' of makefile '/orcle/app/dbhome23ai/network/lib/ins_net_server.mk'.
Error in invoking target 'itrcroute' of makefile '/orcle/app/dbhome23ai/network/lib/ins_net_client.mk'.
Error in invoking target 'irman' of makefile '/orcle/app/dbhome23ai/rdbms/lib/ins_rdbms.mk'.
Error in invoking target 'ioracle' of makefile '/orcle/app/dbhome23ai/rdbms/lib/ins_rdbms.mk'.
There will also be a warning that datapatch did not run.
Для того, чтобы установить Oracle 23AI Free RPM в отдельный ORACLE_HOME на Linux, а не в /opt нужно:
Извлечь из RPM пакета файлы, в нём один cpio архив. Для этой цели я использовал 7zip из под Windows(100% в Linux что-то тоже есть, но я ленивый)))).
Далее, извлекаем файлы из cpio архива: cpio -idv < ./oracle-database-free-23ai-1.0-1.x86_64.cpio
После распаковки архива, в текущей директории вы получите ./etc ./opt ./usr
В папке ./opt/oracle/product/23ai/dbhomeFree находится то что нам нужно, дистрибутив для установки. Папку ./user можно дропнуть, папку ./etc можно изучить.
Копируем/Перемещаем папку dbhomeFree в нужный нам ORACLE_HOME и запускаем ./runInstaller
Установка, рекомендую выбрать Software Only, а уже потом через dbca развернуть бд. При установке вы можете выбрать любую редакцию, но толку от этого ноль. Также будут ошибки, порядка 18, связанные с линковкой библиотек, пример:
Error in invoking target 'install' of makefile '/orcle/app/dbhome23ai/srvm/lib/ins_srvm.mk'.
Error in invoking target 'utilities' of makefile '/orcle/app/dbhome23ai/rdbms/lib/ins_rdbms.mk'.
Error in invoking target 'iokdstry iokinit' of makefile '/orcle/app/dbhome23ai/network/lib/ins_nau.mk'.
Error in invoking target 'install' of makefile '/orcle/app/dbhome23ai/network/lib/ins_net_server.mk'.
Error in invoking target 'itrcroute' of makefile '/orcle/app/dbhome23ai/network/lib/ins_net_client.mk'.
Error in invoking target 'irman' of makefile '/orcle/app/dbhome23ai/rdbms/lib/ins_rdbms.mk'.
Error in invoking target 'ioracle' of makefile '/orcle/app/dbhome23ai/rdbms/lib/ins_rdbms.mk'.
Так же, будет предупреждение, что не отработал datapatch. Не смотря на все ошибки, бд работает.
Many probably know that frequent commits are bad and slow, but how bad and how slow is not clear, and this small test is designed to demonstrate the impact of this event.
I’ll note right away that commits should be made exactly when the business process requires it, or when there is any other significant reason, rather than just ‘in case.’
Test environment:
Oracle 19.23
OS: OEL 8.5 4.18.0-513.24.1.el8_9.x86_64
RAM: 128GB
CPU: AMD Threadripper 1920x
Disks:
Disk group for data files: +ORADATA: SATA SSD GeIL R3 512GB
Disk group for redo logs: +ADATAD1: XPG GAMMIX S11 Pro PCI E 3.0 x4
Disk group for archive logs: +ARCHLOG: SATA SSD GeIL R3 512GB
+ORADATA and +ARCHLOG are located on the same physical disk SATA SSD GeIL R3 512GB.
The code that will act as the load (intensive business process activity):
Variant 1:
declare
v_loop number;
v_seq number;
v_text varchar2(3000);
v_rtext varchar2(3000);
begin
execute immediate 'truncate table t1';
dbms_output.put_line('Start: '||to_char(sysdate,'dd.mm.yyyy hh24:mi:ss'));
dbms_workload_repository.create_snapshot;
v_loop:=1;
select dbms_random.string(opt => 'X',len => 3000) into v_rtext from dual;
while v_loop<5000001
loop
v_seq:=t1_seq.nextval;
insert into t1(id,text) values(v_seq,v_rtext);
commit write wait;
select t1.text into v_text from t1 where id=v_seq;
update t1 set t1.text='update' where id=v_seq;
commit write wait;
delete from t1 where id=v_seq;
commit write wait;
v_loop:=v_loop+1;
end loop;
dbms_workload_repository.create_snapshot;
dbms_output.put_line('End: '||to_char(sysdate,'dd.mm.yyyy hh24:mi:ss'));
end;
Variant 2:
declare
v_loop number;
v_seq number;
v_text varchar2(3000);
v_rtext varchar2(3000);
begin
execute immediate 'truncate table t1';
dbms_output.put_line('Start: '||to_char(sysdate,'dd.mm.yyyy hh24:mi:ss'));
dbms_workload_repository.create_snapshot;
v_loop:=1;
select dbms_random.string(opt => 'X',len => 3000) into v_rtext from dual;
while v_loop<5000001
loop
v_seq:=t1_seq.nextval;
insert into t1(id,text) values(v_seq,v_rtext);
select t1.text into v_text from t1 where id=v_seq;
update t1 set t1.text='update' where id=v_seq;
delete from t1 where id=v_seq;
commit write wait;
v_loop:=v_loop+1;
end loop;
dbms_workload_repository.create_snapshot;
dbms_output.put_line('End: '||to_char(sysdate,'dd.mm.yyyy hh24:mi:ss'));
end;
The difference between the first and second options is that the first option has 3 commits within the loop, while the second has 1 commit within the loop. Also, the ‘commit write wait’ construct is chosen to avoid PL/SQL optimization, as this commit variant is used if the code is not written in PL/SQL.
Variant 1 took 23 minutes and 6 seconds (1386 seconds) to complete.
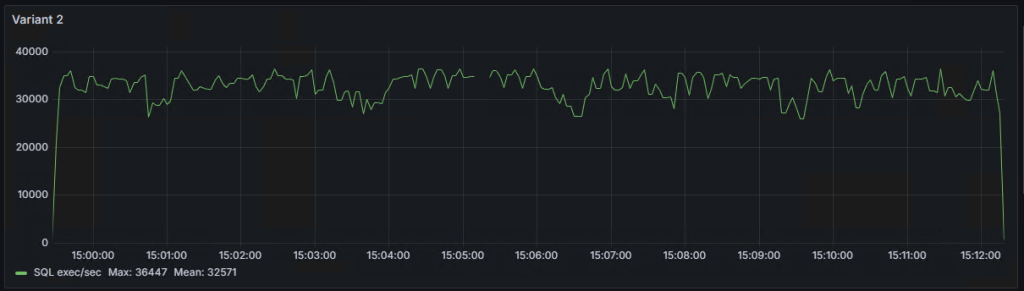
Variant 2 took 12 minutes and 51 seconds (771 seconds) to complete.
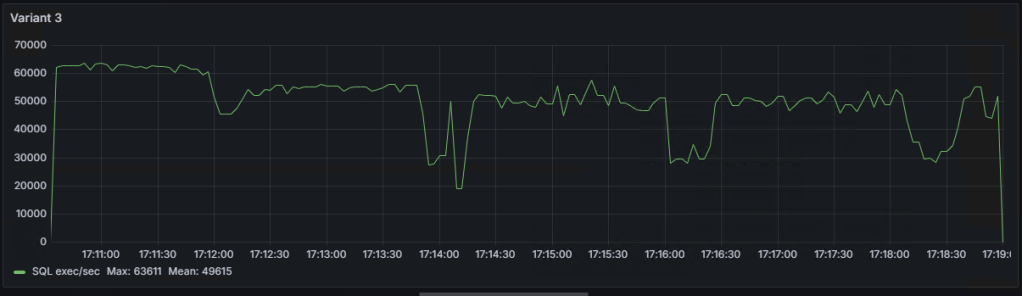
Variant 3 (commit executed only at the end of the loop) took 503 seconds, but it’s not considered for evaluation.
So, Variant 2 is nearly twice as fast.
Reasons why Variant 1 took longer:
Further calculations are done with a certain margin of error, and it is assumed that all statistics relate only to the tasks being performed.
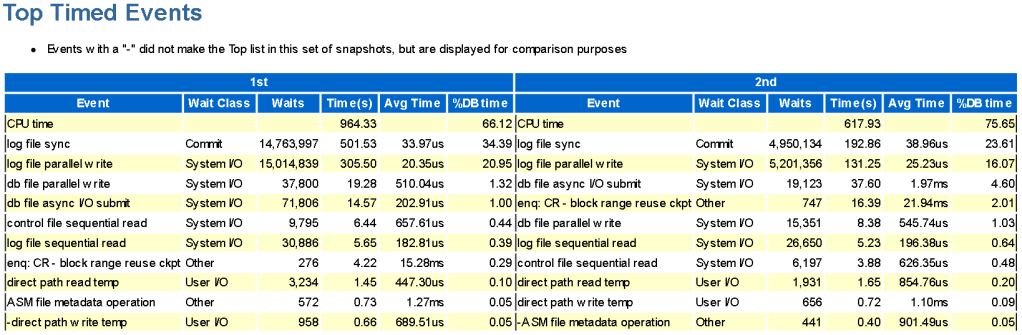
Variant 1 took 501 seconds for log file sync (lfs) out of 1386 seconds, while variant 2 took 192 seconds for log file sync (lfs) out of 771 seconds. By subtracting 501 from 1386, we get 885 seconds. Mathematically excluding all intermediate commits in the loop from variant 1, it still takes more time than variant 2, with 885 seconds versus 771 seconds.
Graph of the number of SQL statement executions per second for ‘Variant 1,’ ‘Variant 2,’ and ‘Variant 3’:
As seen on the graphs, there are some ‘dips,’ the explanations for which I will try to provide in the following note.
Многие наверно знают, что частые коммиты — это плохо и медленно, но насколько плохо и насколько медленно, не понятно и данный маленький тест призван показать влияние этого события.
Сразу отмечу, что выполнять коммит нужно ровно тогда, когда этого требует бизнес-процесс, либо имеется любая другая веская причина, а не просто “на всякий случай”.
Тестовый стенд:
Oracle 19.23
OS: OEL 8.5 4.18.0-513.24.1.el8_9.x86_64
RAM: 128GB
CPU: AMD Threadripper 1920x
Диски:
Дисковая группа для датафайлов: +ORADATA: SATA SSD GeIL R3 512GB
Дисковая группа для редологов: +ADATAD1: XPG GAMMIX S11 Pro PCI E 3.0 х4
Дисковая группа для архивных логов: +ARCHLOG: SATA SSD GeIL R3 512GB
+ORADATA и +ARCHLOG расположены на одном физическом диске SATA SSD GeIL R3 512GB.
Код, который будет выступать в виде нагрузки (бурной деятельности бизнес-процессов):
Вариант номер 1:
declare
v_loop number;
v_seq number;
v_text varchar2(3000);
v_rtext varchar2(3000);
begin
execute immediate 'truncate table t1';
dbms_output.put_line('Start: '||to_char(sysdate,'dd.mm.yyyy hh24:mi:ss'));
dbms_workload_repository.create_snapshot;
v_loop:=1;
select dbms_random.string(opt => 'X',len => 3000) into v_rtext from dual;
while v_loop<5000001
loop
v_seq:=t1_seq.nextval;
insert into t1(id,text) values(v_seq,v_rtext);
commit write wait;
select t1.text into v_text from t1 where id=v_seq;
update t1 set t1.text='update' where id=v_seq;
commit write wait;
delete from t1 where id=v_seq;
commit write wait;
v_loop:=v_loop+1;
end loop;
dbms_workload_repository.create_snapshot;
dbms_output.put_line('End: '||to_char(sysdate,'dd.mm.yyyy hh24:mi:ss'));
end;
Вариант номер 2:
declare
v_loop number;
v_seq number;
v_text varchar2(3000);
v_rtext varchar2(3000);
begin
execute immediate 'truncate table t1';
dbms_output.put_line('Start: '||to_char(sysdate,'dd.mm.yyyy hh24:mi:ss'));
dbms_workload_repository.create_snapshot;
v_loop:=1;
select dbms_random.string(opt => 'X',len => 3000) into v_rtext from dual;
while v_loop<5000001
loop
v_seq:=t1_seq.nextval;
insert into t1(id,text) values(v_seq,v_rtext);
select t1.text into v_text from t1 where id=v_seq;
update t1 set t1.text='update' where id=v_seq;
delete from t1 where id=v_seq;
commit write wait;
v_loop:=v_loop+1;
end loop;
dbms_workload_repository.create_snapshot;
dbms_output.put_line('End: '||to_char(sysdate,'dd.mm.yyyy hh24:mi:ss'));
end;
Отличие первого и второго варианта в том, что первый вариант имеет 3 коммита в цикле, а второй 1 коммит в цикле. Также, конструкция commit write wait выбрана для того, чтобы избежать оптимизации PL/SQL, т.к. данный вариант коммита применяется если код написан не на PL/SQL.
Вариант 1, выполнился за 23 минуты и 6 секунд(1386 секунд)
Вариант 2, выполнился за 12 минут и 51 секунду(771 секунд).
В не зачёта: Вариант 3(коммит выполняется только по окончанию цикла), выполнился за 503 секунды.
Т.е. вариант 2 быстрее почти в 2 раза.
На что вариант 1 потратил время(почему он медленнее):
Далее расчеты делаются с определённой погрешностью и предполагается, что все статистики относятся только к выполняемым задачам.
Вариант 1 из 1386 секунд, потратил на log file sync(lfs) 501 сек, а вариант 2 из 771 секунд, потратил на log file sync(lfs) 192 сек. Отняв от 1386, 501, получим 885 сек, т.е. математически исключим все промежуточные коммиты в цикле из варианта 1, всё равно вариант 1 затрачивает времени больше, чем вариант 2, 885сек против 771сек.
График количества выполнений SQL выражений в секунду для “вариант 1”,“вариант 2” и “вариант 3”:
Как видно на графиках, есть некие “провалы”, объяснения которым я попробую дать в следующей заметке.
After installing DBRU19.19 on 19.9, one table started to grow linearly. The table is a buffer, with insertion and almost immediate deletion. The table consistently holds around 1000 rows, but its volume increases every day. Upon searching on Oracle Support, Bug 30265523 was found — blocks are not marked as free in Automatic Segment Space Management (ASSM) after deletion — 12.2 and later (Doc ID 30265523.8).
After dumping the first level bitmap block of free space in the extent, I see the following picture:
We observe rejection code 3, and all blocks are marked as FULL. This fully coincides with the description of the bug, which supposedly has been fixed. If we dump a block with data, there will be only one row in it, marked as deleted (—HDFL—). It is worth noting that the problematic table has several varchar2(4000) fields, out of which always two fields are filled up to the brim, and sometimes three fields, while the rest are always null. The table does not have any chained and migrated rows.
Further experiments have shown that:
Disabling or setting _enable_rejection_cache = false does not help or worsens the situation.
Disabling _assm_segment_repair_bg=false does not help either.
The combination of _enable_rejection_cache = false and _fix_control=’32075777:ON’ does not help either.
The potential solution (a workaround) may only be setting one parameter: _fix_control=’32075777:ON’.
Setting _fix_control=’32075777:ON’ has helped maintain the table within normal size limits. Under constant load, the table stopped growing. With the same load, in 19.9 the table had a size of a couple of hundred megabytes, while in 19.19 with _fix_control=’32075777:ON’, the growth stopped at around 1GB. Also, upon setting _fix_control=’32075777:ON’, a non-zero metric ASSM_bg_slave_fix_state appeared, which apparently increases after fixing the status of blocks in the bitmap, and x$ktsp_repair_list started to fill up (I assume this displays a list of segments on which the segment repair mechanism has been activated). I have opened an SR.
Overall, how has the operation of ASSM changed? Before 06/21, the database was running on DBRU 19.9, and after 6/20, on 19.19.
Issue: There is a dead transaction rolling back at a rate of 1-2 blocks per second, blocking the execution of update/delete/insert with a wait for transaction (event#=1074, name=transaction). Oracle Version: 19.21.
Since transaction rollback can take a considerable amount of time, it’s essential to assist this process. To do this, you need to drop the object associated with the transaction causing the slow rollback. How to determine the object that needs to be dropped? This might not be straightforward because the transaction could involve multiple tables. In my case, I enabled tracing 10046 for the SMON process, in which there were waits like ‘enq: CR — block range reuse ckpt’ obj#=MyProblematicObject. Additionally, I dumped the header of the undo segment (alter system dump undo header «_SegmentName») and the undo blocks associated with the transaction (alter system dump undo block «_SegmentName» XID number_USN number_SLT number_SEQ).
Where do we get what?
USN, SLT,SEQ- from select * from v$fast_start_transactions
_SegmentName- from Select * from v$rollname where usn = USN
In the dump of blocks associated with the transaction, there is a lot of this:
There are suspicions that KTSL stands for Kernel Transaction Segment LOB, but this is not certain. In the dump of the undo header and in the dump of blocks associated with the transaction, there should be a connection as follows: in the undo segment header in the TRN TBL section, the cmt column has a value of 0, and in the dba column at the same level, there are coordinates of the block. Dumping this block, we will enter the UBA, which is associated with ‘alter system dump undo block «_SegmentName» XID number_USN number_SLT number_SEQ’
After analyzing a lot of text, I select the necessary object and drop it.))
alter system set "_smu_debug_mode"=1024;
oradebug setospid <ospid of SMON process>
oradebug event 10513 trace name context forever, level 2
drop table owner.table purge;
purge recyclebin;
oradebug event 10513 trace name context off
alter system set "_smu_debug_mode"=0;
Also, I used fast_start_parallel_rollback=false; (changing this parameter can stop the rollback process, either the instance needs to be restarted or attempt to revive SMON)
Useful notes:
Database Hangs Because SMON Is Taking 100% CPU Doing Transaction Recovery (Doc ID 414242.1)
IF: Transaction Recovery or Rollback of Dead Transactions (Doc ID 1951738.1)
I would like to highlight:
Bug 11790175 — SMON spins in rollback of LOB due to double allocated block like bug 11814891 (Doc ID 11790175.8)
This is an ancient bug, the description of which in my case coincides only on two criteria: Slow rollback Problematic object is LOB.
UNDO and REDO, a complex topic… perhaps there is a simpler method.
В среде Windows 10 кэш на запись отключается в диспетчере устройств ->Дисковые устройства. Выберем свойство диска, вкладка «Политика».
Под правильными тестами IO, я имею ввиду получения адекватного латенси от дисков, как на чтение так и на запись при устоявшейся нагрузке. Не отключив кэш на запись, результаты тестов будут не воспроизводимыми, ввиду того, что кэш на запись всё время всё портит.