DB version: Oracle 19.9 x86.
In this note, I will visually demonstrate how the transition of lgwr from poll->post to post/wait mode can look like.
Investigate time when it happened by using trace file of lgwr process:
*** 2023-02-16T12:45:09.010167+06:00
Log file sync switching to post/wait
Current approximate redo synch write rate is 10286 per sec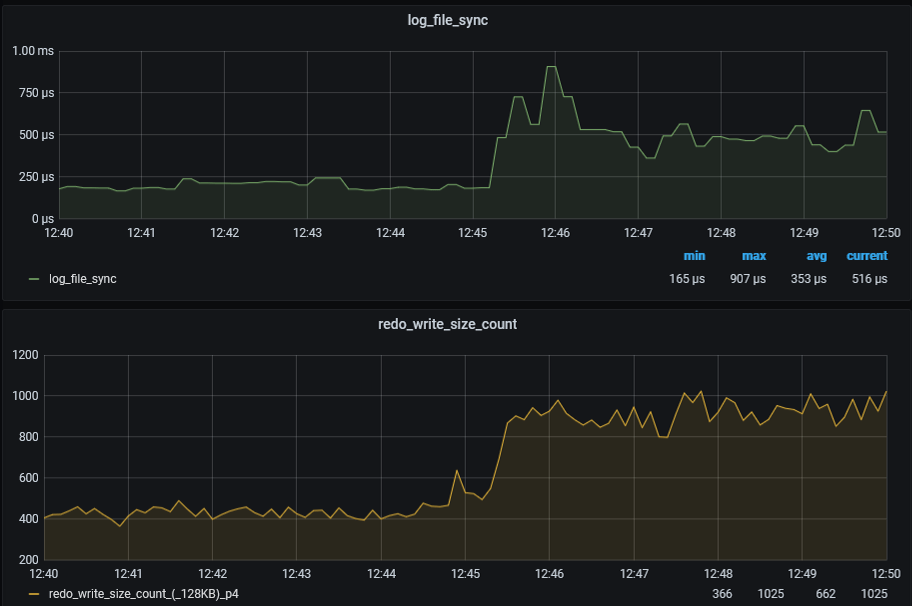

Figure 1 shows that the transition of lgwr from poll->post to post/wait mode led to a doubling of the log file sync wait time, from 250 microseconds to 500 microseconds.
Additionally, the number of redo blocks written in 128KB doubled. Although not visible in the graphs, there is also a decrease in the number of redo blocks written that are much smaller than 128KB (4, 8, 16, 32KB, etc).
Figure 2 shows how the number of log file parallel write waits (oracledb_event_p3_log_file_parallel_write_p2) has changed.
The number of waits has decreased by half, but the duration of a single log file parallel write wait (oracledb_event_p2_log_file_parallel_write_p2) has increased by an average of 50%, from 50 microseconds to 75 microseconds.
It looks like some sort of ferry mode where fewer operations are performed with larger block sizes, resulting in a 2x reduction in response time. This behavior is subject to change according to the algorithm and database parameters associated with the adaptive operation of LGWR.
You can read more here:
- Adaptive Switching Between Log Write Methods can Cause ‘log file sync’ Waits (Doc ID 1462942.1)
- ADAPTIVE LOG FILE SYNC: ORACLE, PLEASE DON’T DO THAT AGAIN
Actually, the solution is: ALTER SYSTEM SET «_use_adaptive_log_file_sync» = FALSE;
